- Cover
- Acknowledgments
- 1 Preface
- 2 (R)e-Introduction to statistics
- 2.1 Histograms, boxplots, and density curves
- 2.2 Pirate-plots
- 2.3 Models, hypotheses, and permutations for the two sample mean situation
- 2.4 Permutation testing for the two sample mean situation
- 2.5 Hypothesis testing (general)
- 2.6 Connecting randomization (nonparametric) and parametric tests
- 2.7 Second example of permutation tests
- 2.8 Reproducibility Crisis: Moving beyond p < 0.05, publication bias, and multiple testing issues
- 2.9 Confidence intervals and bootstrapping
- 2.10 Bootstrap confidence intervals for difference in GPAs
- 2.11 Chapter summary
- 2.12 Summary of important R code
- 2.13 Practice problems
- 3 One-Way ANOVA
- 3.1 Situation
- 3.2 Linear model for One-Way ANOVA (cell-means and reference-coding)
- 3.3 One-Way ANOVA Sums of Squares, Mean Squares, and F-test
- 3.4 ANOVA model diagnostics including QQ-plots
- 3.5 Guinea pig tooth growth One-Way ANOVA example
- 3.6 Multiple (pair-wise) comparisons using Tukey’s HSD and the compact letter display
- 3.7 Pair-wise comparisons for the Overtake data
- 3.8 Chapter summary
- 3.9 Summary of important R code
- 3.10 Practice problems
- 4 Two-Way ANOVA
- 4.1 Situation
- 4.2 Designing a two-way experiment and visualizing results
- 4.3 Two-Way ANOVA models and hypothesis tests
- 4.4 Guinea pig tooth growth analysis with Two-Way ANOVA
- 4.5 Observational study example: The Psychology of Debt
- 4.6 Pushing Two-Way ANOVA to the limit: Un-replicated designs and Estimability
- 4.7 Chapter summary
- 4.8 Summary of important R code
- 4.9 Practice problems
- 5 Chi-square tests
- 5.1 Situation, contingency tables, and tableplots
- 5.2 Homogeneity test hypotheses
- 5.3 Independence test hypotheses
- 5.4 Models for R by C tables
- 5.5 Permutation tests for the \(X^2\) statistic
- 5.6 Chi-square distribution for the \(X^2\) statistic
- 5.7 Examining residuals for the source of differences
- 5.8 General protocol for \(X^2\) tests
- 5.9 Political party and voting results: Complete analysis
- 5.10 Is cheating and lying related in students?
- 5.11 Analyzing a stratified random sample of California schools
- 5.12 Chapter summary
- 5.13 Summary of important R commands
- 5.14 Practice problems
- 6 Correlation and Simple Linear Regression
- 6.1 Relationships between two quantitative variables
- 6.2 Estimating the correlation coefficient
- 6.3 Relationships between variables by groups
- 6.4 Inference for the correlation coefficient
- 6.5 Are tree diameters related to tree heights?
- 6.6 Describing relationships with a regression model
- 6.7 Least Squares Estimation
- 6.8 Measuring the strength of regressions: R2
- 6.9 Outliers: leverage and influence
- 6.10 Residual diagnostics – setting the stage for inference
- 6.11 Old Faithful discharge and waiting times
- 6.12 Chapter summary
- 6.13 Summary of important R code
- 6.14 Practice problems
- 7 Simple linear regression inference
- 7.1 Model
- 7.2 Confidence interval and hypothesis tests for the slope and intercept
- 7.3 Bozeman temperature trend
- 7.4 Randomization-based inferences for the slope coefficient
- 7.5 Transformations part I: Linearizing relationships
- 7.6 Transformations part II: Impacts on SLR interpretations: log(y), log(x), & both log(y) & log(x)
- 7.7 Confidence interval for the mean and prediction intervals for a new observation
- 7.8 Chapter summary
- 7.9 Summary of important R code
- 7.10 Practice problems
- 8 Multiple linear regression
- 8.1 Going from SLR to MLR
- 8.2 Validity conditions in MLR
- 8.3 Interpretation of MLR terms
- 8.4 Comparing multiple regression models
- 8.5 General recommendations for MLR interpretations and VIFs
- 8.6 MLR inference: Parameter inferences using the t-distribution
- 8.7 Overall F-test in multiple linear regression
- 8.8 Case study: First year college GPA and SATs
- 8.9 Different intercepts for different groups: MLR with indicator variables
- 8.10 Additive MLR with more than two groups: Headache example
- 8.11 Different slopes and different intercepts
- 8.12 F-tests for MLR models with quantitative and categorical variables and interactions
- 8.13 AICs for model selection
- 8.14 Case study: Forced expiratory volume model selection using AICs
- 8.15 Chapter summary
- 8.16 Summary of important R code
- 8.17 Practice problems
- 9 Case studies
- 9.1 Overview of material covered
- 9.2 The impact of simulated chronic nitrogen deposition on the biomass and N2-fixation activity of two boreal feather moss–cyanobacteria associations
- 9.3 Ants learn to rely on more informative attributes during decision-making
- 9.4 Multi-variate models are essential for understanding vertebrate diversification in deep time
- 9.5 What do didgeridoos really do about sleepiness?
- 9.6 General summary
- References
2.4 Permutation testing for the two sample mean situation
In any testing situation, you must define some function of the observations that gives us a single number that addresses our question of interest. This quantity is called a test statistic. These often take on complicated forms and have names like \(t\) or \(z\) statistics that relate to their parametric (named) distributions so we know where to look up p-values28. In randomization settings, they can have simpler forms because we use the data set to find the distribution of the statistic under the null hypothesis and don’t need to rely on a named distribution. We will label our test statistic T (for Test statistic) unless the test statistic has a commonly used name. Since we are interested in comparing the means of the two groups, we can define
\[T=\bar{x}_\text{commute} - \bar{x}_\text{casual},\]
which coincidentally is what the diffmean function and the second coefficient from the lm provided us previously.
We label our observed test statistic (the one from the original data
set) as
\[T_{obs}=\bar{x}_\text{commute} - \bar{x}_\text{casual},\]
which happened to be -25.933 cm here. We will compare this result to the results for the test statistic that we obtain from permuting the group labels. To denote permuted results, we will add a * to the labels:
\[T^*=\bar{x}_{\text{commute}^*}-\bar{x}_{\text{casual}^*}.\]
We then compare the \(T_{obs}=\bar{x}_\text{commute} - \bar{x}_\text{casual} = -25.933\) to the distribution of results that are possible for the permuted results (\(T^*\)) which corresponds to assuming the null hypothesis is true.
We need to consider lots of permutations to do a permutation test.
In contrast to
your introductory statistics course where, if you did this, it was just a click
away, we are going to learn what was going on “under the hood” of the software you were using. Specifically, we
need a for loop in R to be able to repeatedly generate the permuted data
sets and record \(T^*\) for each one. Loops are a basic programming task that make
randomization methods possible as well as potentially simplifying any repetitive
computing task. To write a “for loop”, we need to choose how many times we want
to do the loop (call that B) and decide on a counter to keep track of where
we are at in the loops (call that b, which goes from 1 up to B). The
simplest loop just involves printing out the index, print(b) at each step.
This is our first use of curly braces, { and }, that are used to group the code
we want to repeatedly run as we proceed through the loop. By typing the following
code in a codechunk and then highlighting it all and hitting the run button,
R will go through the loop B = 5 times, printing out the counter:
B <- 5
for (b in (1:B)){
print(b)
}Note that when you highlight and run the code, it will look about the same with “+” printed after the first line to indicate that all the code is connected when it appears in the console, looking like this:
When you run these three lines of code (or compile a .Rmd file that contains this), the console will show you the following output:
Instead of printing the counter, we want to use the loop to repeatedly compute
our test statistic across B random permutations of the observations. The
shuffle function performs permutations of the group labels relative to
responses and the coef(lmP)[2] extracts the estimated difference in the two group means in the permuted
data set. For a single permutation, the combination of shuffling Condition and
finding the difference in the means, storing it in a variable called Ts is:
## shuffle(Condition)commute
## 16.6And putting this inside the print function allows us to find the test
statistic under 5 different permutations easily:
B <- 5
for (b in (1:B)){
lmP <- lm(Distance~shuffle(Condition), data=dsample)
Ts <- coef(lmP)[2]
print(Ts)
}## shuffle(Condition)commute
## -1.8
## shuffle(Condition)commute
## -9.533333
## shuffle(Condition)commute
## 3.8
## shuffle(Condition)commute
## 9.4
## shuffle(Condition)commute
## 26.73333Finally, we would like to store the values of the test statistic instead of
just printing them out on each pass through the loop. To do this, we need to
create a variable to store the results, let’s call it Tstar. We know that
we need to store B results so will create a vector29 of length B, which
contains B elements, full of missing values (NA) using the matrix function with the nrow option specifying the number of elements:
## [,1]
## [1,] NA
## [2,] NA
## [3,] NA
## [4,] NA
## [5,] NANow we can run our loop B times and store the results in Tstar.
for (b in (1:B)){
lmP <- lm(Distance~shuffle(Condition), data=dsample)
Tstar[b] <- coef(lmP)[2]
}
Tstar## [,1]
## [1,] 9.533333
## [2,] 9.933333
## [3,] 23.000000
## [4,] -11.000000
## [5,] -17.400000Five permutations are still not enough to assess whether our \(T_{obs}\)
of -25.933 is unusual and we need to do many permutations to get an accurate
assessment of the possibilities under the null hypothesis.
It is common practice
to consider something like 1,000 permutations. The Tstar vector when we set
B to be large, say B=1000, contains the permutation distribution for the
selected test statistic under30 the null
hypothesis – what is called the null distribution of the statistic. The
null distribution is the distribution of possible values of a statistic
under the null hypothesis. We want to visualize this distribution and use it to
assess how unusual our \(T_{obs}\) result of -25.933 cm was relative to all the
possibilities under permutations (under the null hypothesis). So we repeat the
loop, now with \(B=1000\) and generate a histogram, density curve, and summary
statistics of the results:
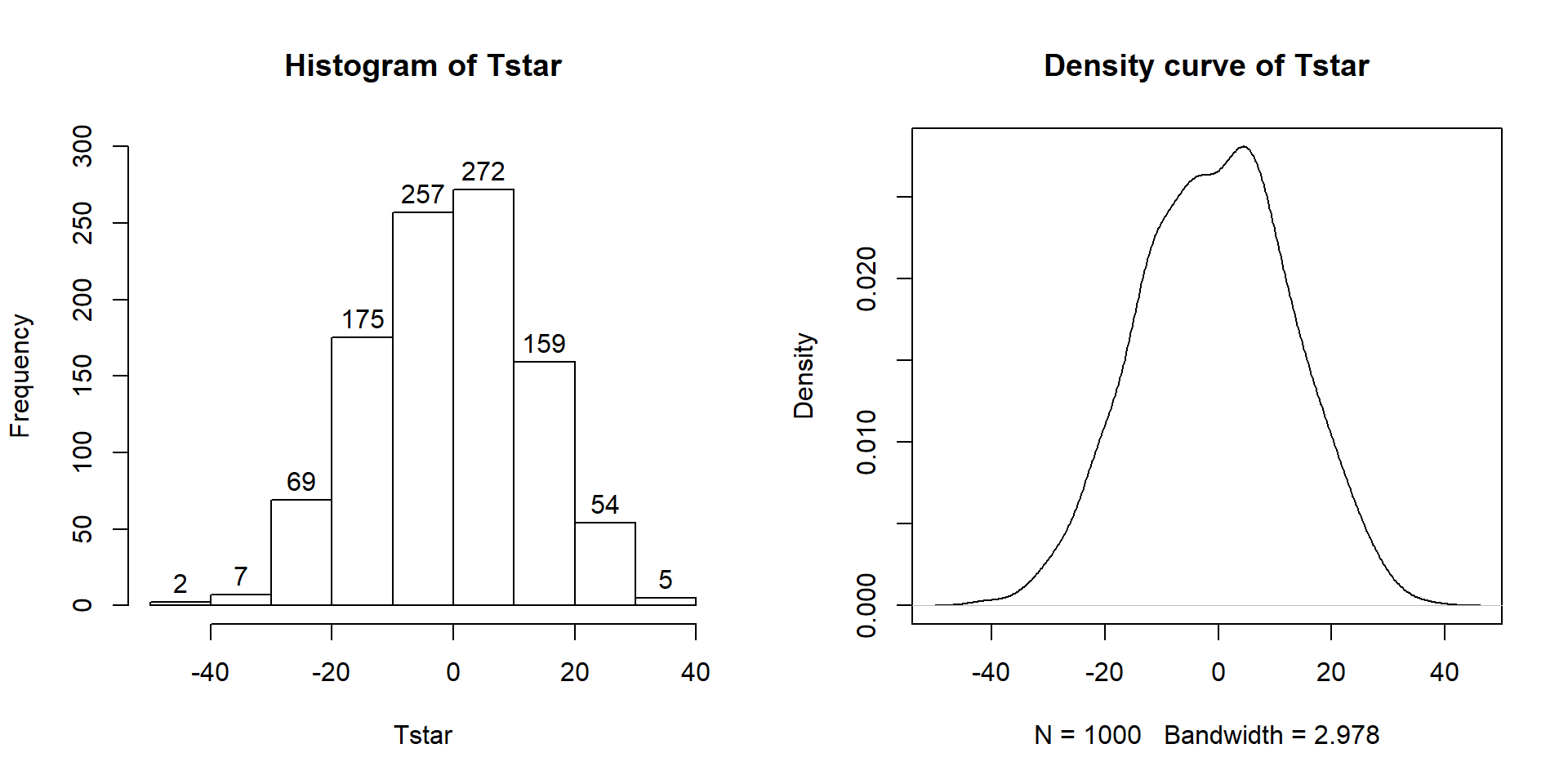
Figure 2.9: Histogram (left, with counts in bars) and density curve (right) of values of test statistic for B = 1,000 permutations.
B <- 1000
Tstar <- matrix(NA, nrow=B)
for (b in (1:B)){
lmP <- lm(Distance~shuffle(Condition), data=dsample)
Tstar[b] <- coef(lmP)[2]
}
hist(Tstar, label=T,ylim=c(0,300))
plot(density(Tstar), main="Density curve of Tstar")## min Q1 median Q3 max mean sd n
## -41.26667 -10.06667 -0.3333333 8.6 37.26667 -0.5054667 13.17156 1000
## missing
## 0Figure 2.9 contains visualizations of \(T^*\) and the favstats
summary provides the related numerical summaries. Our observed \(T_{obs}\)
of -25.933 seems somewhat unusual relative to these results with only
9 \(T^*\) values smaller than -30 based on the
histogram. We need to make more specific comparisons of the permuted results
versus our observed result to be able to clearly decide whether our observed
result is really unusual.
To make the comparisons more concrete, first we can enhance the previous graphs
by adding the value of the test statistic from the real data set, as shown in
Figure 2.10, using the abline function to draw a vertical
line at our \(T_{obs}\) value specified in the v (for vertical) option.
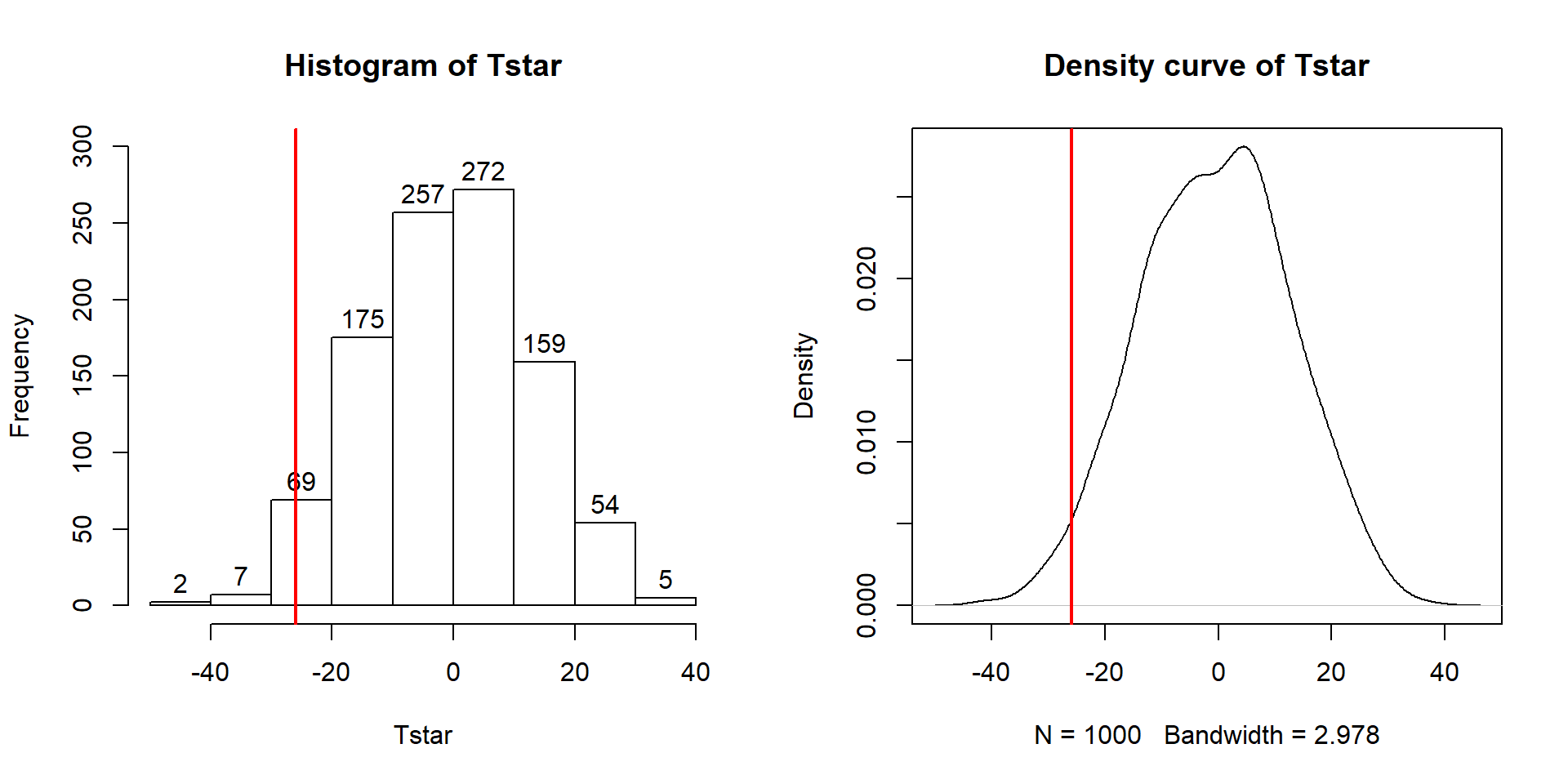
Figure 2.10: Histogram (left) and density curve (right) of values of test statistic for 1,000 permutations with bold vertical line for value of observed test statistic.
Tobs <- -25.933
hist(Tstar, labels=T)
abline(v=Tobs, lwd=2, col="red")
plot(density(Tstar), main="Density curve of Tstar")
abline(v=Tobs, lwd=2, col="red")Second, we can calculate the exact number of permuted results that were as
small or smaller
than what we observed. To calculate the proportion of the 1,000 values that were
as small or smaller than what we observed, we will use the pdata function.
To use this
function, we need to provide the distribution of values to compare to the cut-off
(Tstar), the cut-off point (Tobs), and whether we want calculate the
proportion that are below (left of) or above (right of) the cut-off
(lower.tail=T option provides the proportion of values to the left of (below) the cutoff
of interest).
## [1] 0.027The proportion of 0.027 tells us that 27 of the 1,000 permuted results (2.7%) were as small or smaller than what we observed. This type of work is how we can generate p-values using permutation distributions. P-values, as you should remember, are the probability of getting a result as extreme as or more extreme than what we observed, \(\underline{\text{given that the null is true}}\). Finding only 27 permutations of 1,000 that were as small or smaller than our observed result suggests that it is hard to find a result like what we observed if there really were no difference, although it is not impossible.
When testing hypotheses for two groups, there are two types of alternative
hypotheses, one-sided or two-sided. One-sided tests involve only considering
differences in one-direction (like \(\mu_1 > \mu_2\)) and are performed when
researchers can decide a priori31 which group should have a larger mean
if there is going to be any sort of difference. In this situation, we did not
know enough about the potential impacts of the outfits to know which group should
be larger than the other so should do a two-sided test. It is important to
remember that you can’t look at the responses to decide on the hypotheses. It is
often safer and more conservative32 to start with a
two-sided alternative (\(\mathbf{H_A: \mu_1 \ne \mu_2}\)). To do a 2-sided
test, find the area smaller than what we observed as above (or larger if the test statistic had been positive). We also need to add
the area in the other tail (here the right tail) similar to what we observed in the
right tail. Some statisticians suggest doubling the area in one tail but we will collect
information on the number that were as or more extreme than the same
value in the other
tail33. In other words, we count the proportion below -25.933 and over 25.933. So
we need to find how many of the permuted results were larger than or equal
to 25.933 cm
to add to our previous proportion. Using pdata with -Tobs as the cut-off
and lower.tail =F provides this result:
## [1] 0.017So the p-value to test our null hypothesis of no difference in the true means between the groups is 0.027 + 0.017, providing a p-value of 0.044. Figure 2.11 shows both cut-offs on the histogram and density curve.
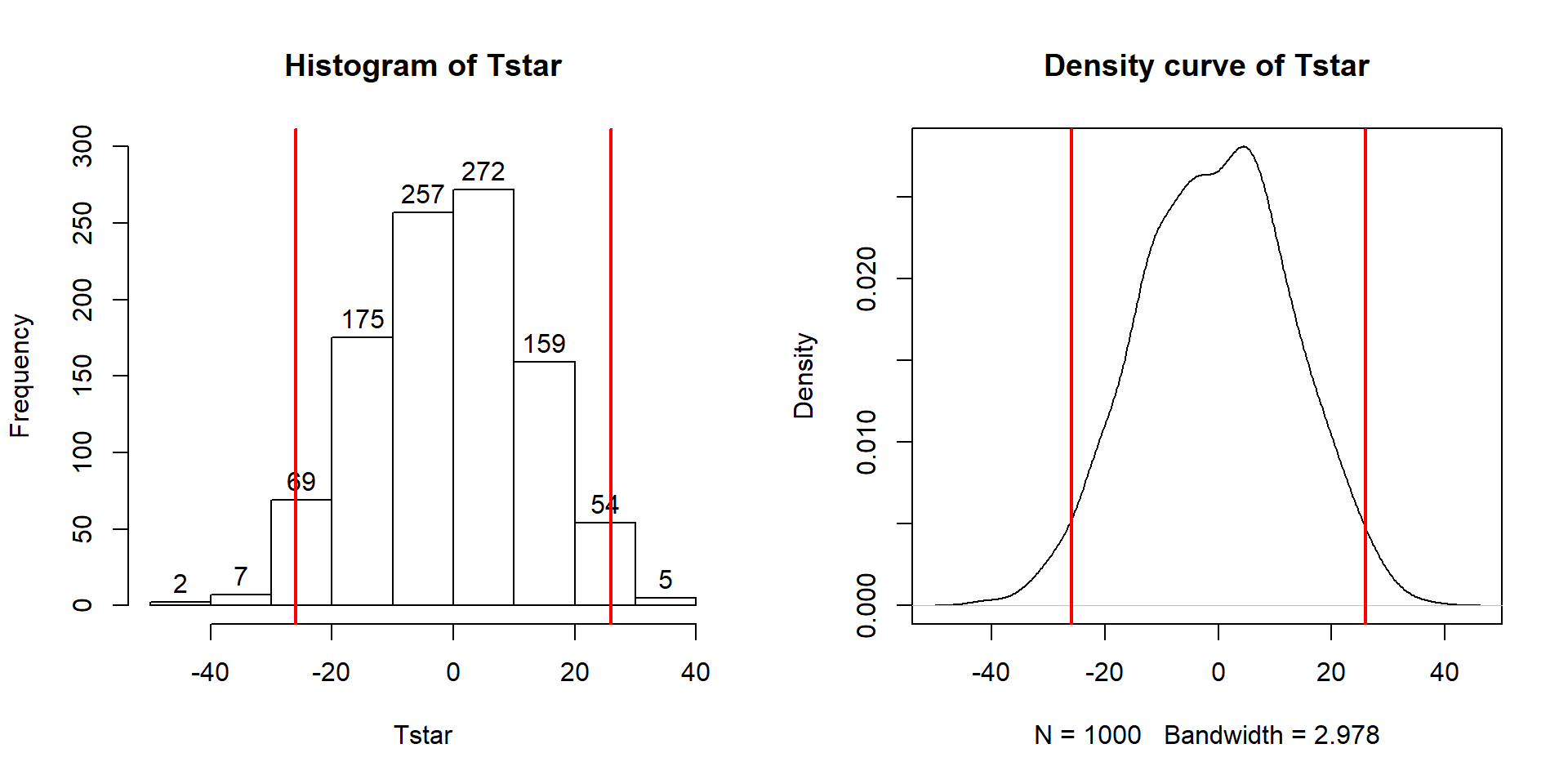
Figure 2.11: Histogram and density curve of values of test statistic for 1,000 permutations with bold lines for value of observed test statistic (-25.933) and its opposite value (25.933) required for performing the two-sided test.
hist(Tstar, labels=T)
abline(v=c(-1,1)*Tobs, lwd=2, col="red")
plot(density(Tstar), main="Density curve of Tstar")
abline(v=c(-1,1)*Tobs, lwd=2, col="red")In general, the one-sided test p-value
is the proportion of the
permuted results that are as extreme or more extreme than observed in the
direction of the alternative
hypothesis (lower or upper tail, remembering that this also depends on the
direction of the difference taken). For the two-sided test, the p-value
is the
proportion of the permuted results that are less than or equal to the negative
version of the observed statistic and greater than or equal to the positive
version of the observed statistic. Using absolute
values (| |), we can simplify this: the two-sided p-value is the
proportion of the |permuted statistics| that are as large or larger than
|observed statistic|.
This will always work and finds areas in both tails regardless of whether the
observed statistic is positive or negative. In R, the abs function provides the
absolute value and we can again use pdata to find our p-value in one line
of code:
## [1] 0.044We will encourage you to think through what might constitute strong evidence against your null hypotheses and then discuss how strong you feel the evidence is against the null hypothesis in the p-value that you obtained. Basically, p-values present a measure of evidence against the null hypothesis, with smaller values presenting more evidence against the null. They range from 0 to 1 and you should interpret them on a graded scale from strong evidence (close to 0) to little evidence to no evidence (1). We will discuss the use of a fixed significance level below as it is still commonly used in many fields and is necessary to discuss to think about the theory of hypothesis testing, but, for the moment, we can conclude that there is moderate evidence against the null hypothesis presented by having a p-value of 0.044 because our observed result is somewhat rare relative to what we would expect if the null hypothesis was true. And so we might conclude (in the direction of the alternative) that there is a difference in the population means in the two groups, but that depends on what you think about how unusual that result was.
Before we move on, let’s note some interesting features of the permutation distribution of the difference in the sample means shown in Figure 2.11.
It is basically centered at 0. Since we are performing permutations assuming the null model is true, we are assuming that \(\mu_1 = \mu_2\) which implies that \(\mu_1 - \mu_2 = 0\). This also suggests that 0 should be the center of the permutation distribution and it was.
It is approximately normally distributed. This is due to the Central Limit Theorem34, where the sampling distribution (distribution of all possible results for samples of this size) of the difference in sample means (\(\bar{x}_1 - \bar{x}_2\)) becomes more normally distributed as the sample sizes increase. With 15 observations in each group, we have no guarantee to have a relatively normal looking distribution of the difference in the sample means but with the distributions of the original observations looking somewhat normally distributed, the sampling distribution of the sample means likely will look fairly normal. This result will allow us to use a parametric method to approximate this sampling distribution under the null model if some assumptions are met, as we’ll discuss below.
Our observed difference in the sample means (-25.933) is a fairly unusual result relative to the rest of these results but there are some permuted data sets that produce more extreme differences in the sample means. When the observed differences are really large, we may not see any permuted results that are as extreme as what we observed. When
pdatagives you 0, the p-value should be reported to be smaller than 0.0001 (not 0!) if B is 1,000 since it happened in less than 1 in 1,000 tries but does occur once – in the actual data set.Since our null model is not specific about the direction of the difference, considering a result like ours but in the other direction (25.933 cm) needs to be included. The observed result seems to put about the same area in both tails of the distribution but it is not exactly the same. The small difference in the tails is a useful aspect of this approach compared to the parametric method discussed below as it accounts for potential asymmetry in the sampling distribution.
Earlier, we decided that the p-value provided moderate evidence against the null hypothesis. You should use your own judgment about whether the p-value obtain is sufficiently small to conclude that you think the null hypothesis is wrong. Remembering that the p-value is the probability you would observe a result like you did (or more extreme), assuming the null hypothesis is true; this tells you that the smaller the p-value is, the more evidence you have against the null. Figure 2.12 provides a diagram of some suggestions for the graded p-value interpretation that you can use. The next section provides a more formal review of the hypothesis testing infrastructure, terminology, and some of things that can happen when testing hypotheses. P-values have been (validly) criticized for the inability of studies to be reproduced, for the bias in publications to only include studies that have small p-values, and for the lack of thought that often accompanies using a fixed significance level to make decisions (and only focusing on that decision). To alleviate some of these criticisms, we recommend reporting the strength of evidence of the result based on the p-value and also reporting and discussing the size of the estimated results (with a measure of precision of the estimated difference). We will explore the implications of how p-values are used in scientific research in Section [SECTIONREFERENCE].
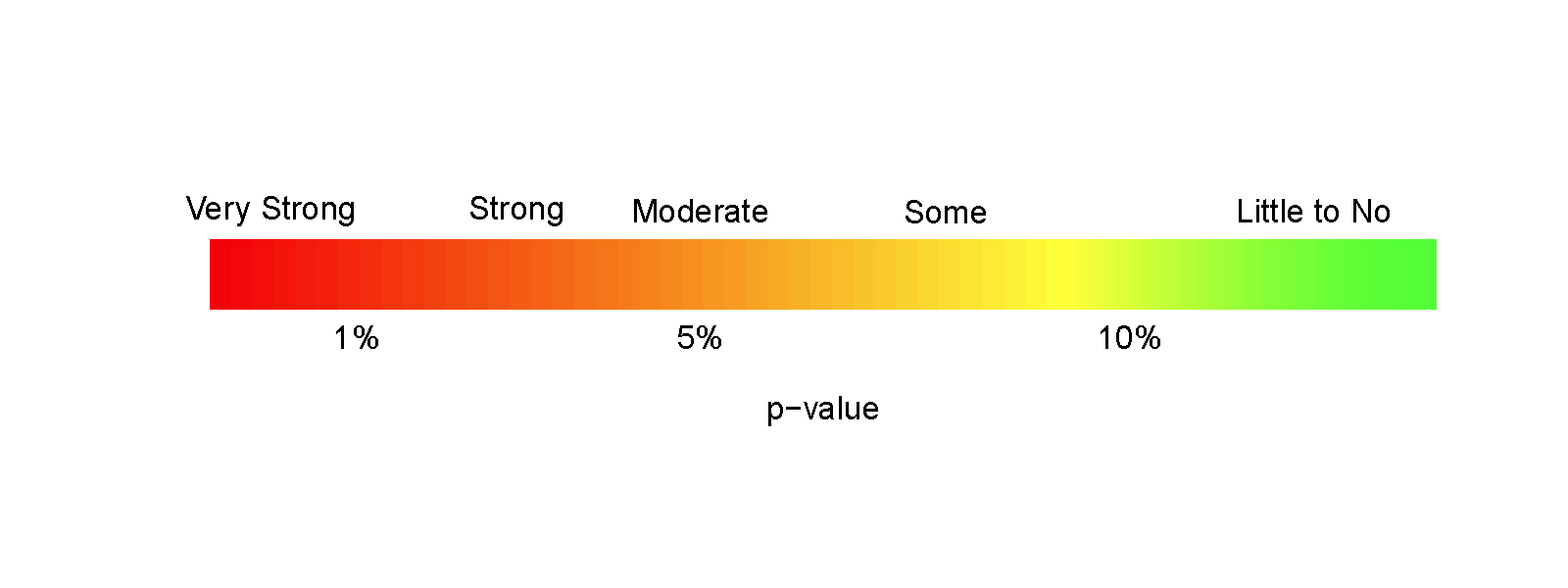
Figure 2.12: Graphic suggesting potential interpretations of strength of evidence based on gradient of p-values.
P-values are the probability of obtaining a result as extreme as or more extreme than we observed given that the null hypothesis is true.↩
In statistics, vectors are one dimensional lists of numeric elements – basically a column from a matrix or our tibble.↩
We often say “under” in statistics and we mean “given that the following is true”.↩
This is a fancy way of saying “in advance”, here in advance of seeing the observations.↩
Statistically, a conservative method is one that provides less chance of rejecting the null hypothesis in comparison to some other method or less than some pre-defined standard. A liberal method provides higher rates of false rejections.↩
Both approaches are reasonable. By using both tails of the distribution we can incorporate potential differences in shape in both tails of the permutation distribution.↩
We’ll leave the discussion of the CLT to your previous statistics coursework or an internet search. For this material, just remember that it has something to do with distributions of statistics looking more normal as the sample size increases.↩