- Cover
- Acknowledgments
- 1 Preface
- 2 (R)e-Introduction to statistics
- 2.1 Histograms, boxplots, and density curves
- 2.2 Pirate-plots
- 2.3 Models, hypotheses, and permutations for the two sample mean situation
- 2.4 Permutation testing for the two sample mean situation
- 2.5 Hypothesis testing (general)
- 2.6 Connecting randomization (nonparametric) and parametric tests
- 2.7 Second example of permutation tests
- 2.8 Reproducibility Crisis: Moving beyond p < 0.05, publication bias, and multiple testing issues
- 2.9 Confidence intervals and bootstrapping
- 2.10 Bootstrap confidence intervals for difference in GPAs
- 2.11 Chapter summary
- 2.12 Summary of important R code
- 2.13 Practice problems
- 3 One-Way ANOVA
- 3.1 Situation
- 3.2 Linear model for One-Way ANOVA (cell-means and reference-coding)
- 3.3 One-Way ANOVA Sums of Squares, Mean Squares, and F-test
- 3.4 ANOVA model diagnostics including QQ-plots
- 3.5 Guinea pig tooth growth One-Way ANOVA example
- 3.6 Multiple (pair-wise) comparisons using Tukey’s HSD and the compact letter display
- 3.7 Pair-wise comparisons for the Overtake data
- 3.8 Chapter summary
- 3.9 Summary of important R code
- 3.10 Practice problems
- 4 Two-Way ANOVA
- 4.1 Situation
- 4.2 Designing a two-way experiment and visualizing results
- 4.3 Two-Way ANOVA models and hypothesis tests
- 4.4 Guinea pig tooth growth analysis with Two-Way ANOVA
- 4.5 Observational study example: The Psychology of Debt
- 4.6 Pushing Two-Way ANOVA to the limit: Un-replicated designs and Estimability
- 4.7 Chapter summary
- 4.8 Summary of important R code
- 4.9 Practice problems
- 5 Chi-square tests
- 5.1 Situation, contingency tables, and tableplots
- 5.2 Homogeneity test hypotheses
- 5.3 Independence test hypotheses
- 5.4 Models for R by C tables
- 5.5 Permutation tests for the \(X^2\) statistic
- 5.6 Chi-square distribution for the \(X^2\) statistic
- 5.7 Examining residuals for the source of differences
- 5.8 General protocol for \(X^2\) tests
- 5.9 Political party and voting results: Complete analysis
- 5.10 Is cheating and lying related in students?
- 5.11 Analyzing a stratified random sample of California schools
- 5.12 Chapter summary
- 5.13 Summary of important R commands
- 5.14 Practice problems
- 6 Correlation and Simple Linear Regression
- 6.1 Relationships between two quantitative variables
- 6.2 Estimating the correlation coefficient
- 6.3 Relationships between variables by groups
- 6.4 Inference for the correlation coefficient
- 6.5 Are tree diameters related to tree heights?
- 6.6 Describing relationships with a regression model
- 6.7 Least Squares Estimation
- 6.8 Measuring the strength of regressions: R2
- 6.9 Outliers: leverage and influence
- 6.10 Residual diagnostics – setting the stage for inference
- 6.11 Old Faithful discharge and waiting times
- 6.12 Chapter summary
- 6.13 Summary of important R code
- 6.14 Practice problems
- 7 Simple linear regression inference
- 7.1 Model
- 7.2 Confidence interval and hypothesis tests for the slope and intercept
- 7.3 Bozeman temperature trend
- 7.4 Randomization-based inferences for the slope coefficient
- 7.5 Transformations part I: Linearizing relationships
- 7.6 Transformations part II: Impacts on SLR interpretations: log(y), log(x), & both log(y) & log(x)
- 7.7 Confidence interval for the mean and prediction intervals for a new observation
- 7.8 Chapter summary
- 7.9 Summary of important R code
- 7.10 Practice problems
- 8 Multiple linear regression
- 8.1 Going from SLR to MLR
- 8.2 Validity conditions in MLR
- 8.3 Interpretation of MLR terms
- 8.4 Comparing multiple regression models
- 8.5 General recommendations for MLR interpretations and VIFs
- 8.6 MLR inference: Parameter inferences using the t-distribution
- 8.7 Overall F-test in multiple linear regression
- 8.8 Case study: First year college GPA and SATs
- 8.9 Different intercepts for different groups: MLR with indicator variables
- 8.10 Additive MLR with more than two groups: Headache example
- 8.11 Different slopes and different intercepts
- 8.12 F-tests for MLR models with quantitative and categorical variables and interactions
- 8.13 AICs for model selection
- 8.14 Case study: Forced expiratory volume model selection using AICs
- 8.15 Chapter summary
- 8.16 Summary of important R code
- 8.17 Practice problems
- 9 Case studies
- 9.1 Overview of material covered
- 9.2 The impact of simulated chronic nitrogen deposition on the biomass and N2-fixation activity of two boreal feather moss–cyanobacteria associations
- 9.3 Ants learn to rely on more informative attributes during decision-making
- 9.4 Multi-variate models are essential for understanding vertebrate diversification in deep time
- 9.5 What do didgeridoos really do about sleepiness?
- 9.6 General summary
- References
6.3 Relationships between variables by groups
In assessing the relationship between variables, incorporating information from a third variable can often enhance the information gathered by either showing that the relationship between the first two variables is the same across levels of the other variable or showing that it differs. When the other variable is categorical (or just can be made categorical), it can be added to scatterplots, changing the symbols and colors for the points based on the different groups. These techniques are especially useful if the categorical variable corresponds to potentially distinct groups in the responses. In the previous example, the data set was built with male and female athletes. For some characteristics, the relationships might be the same for both sexes but for others, there are likely some physiological differences to consider.
We could continue to use the plot function here, but it would require
additional lines of code to add these extra features. The scatterplot
function from the car package (Fox, Weisberg, and Price (2018), Fox and Weisberg (2011)) makes it easy
to incorporate information from an
additional categorical variable. We’ll add to our regular formula idea (y~x)
the vertical line “|” followed by the categorical variable z, such as
y~x|z. As noted earlier, in statistics, “|” means “to condition on” or,
here, consider the relationship between \(y\) and \(x\) by groups in \(z\). The other
options are mainly to make it easier to read the information in the plot…
Using this enhanced notation, Figure 2.106 displays the
Height and Hematocrit relationship with information on the sex of the
athletes where sex was coded 0 for males and 1 for females.
(ref:fig6-7) Scatterplot of athlete’s height and hematocrit by sex of athletes. Males were coded as 0s and females as 1s.
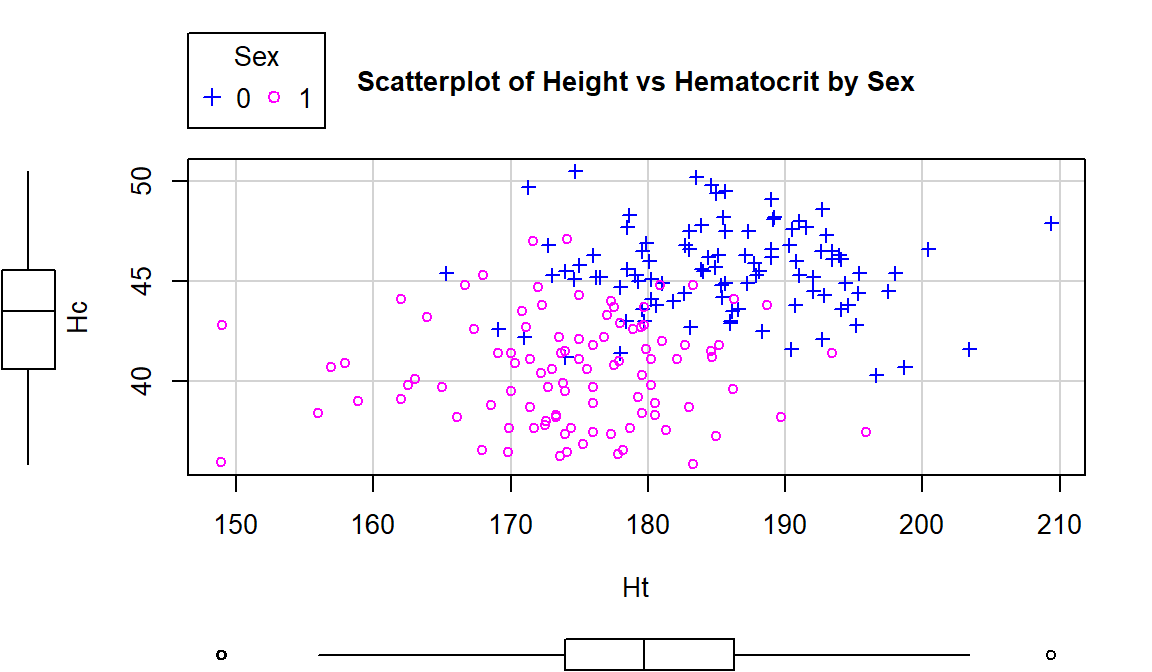
Figure 2.106: (ref:fig6-7)
aisR2 <- ais[-c(56,166),c("Ht","Hc","Bfat","Sex")]
require(car)
aisR2$Sex <- factor(aisR2$Sex)
scatterplot(Hc~Ht|Sex, data=aisR2, pch=c(3,21), regLine=F, smooth=F,
boxplots="xy", main="Scatterplot of Height vs Hematocrit by Sex")
#pch=c(3,21) provides two different symbols that are easy to distinguish. Drop this option or add more numbers to the list if you have more than 2 groups.Adding the grouping information really changes the impressions of the relationship between Height and Hematocrit – within each sex, there is little relationship between the two variables. The overall relationship is of moderate strength and positive but the subgroup relationships are weak at best. The overall relationship is created by inappropriately combining two groups that had different means in both the \(x\) and \(y\) directions. Men have higher mean heights and hematocrit values than women and putting them together in one large group creates the misleading overall relationship95.
To get the correlation coefficients by groups, we can subset the data set using a
logical inquiry on the Sex variable in the updated aisR2 data set, using
Sex==0 in the subset function to get a tibble with male subjects only and Sex==1 for the female subjects,
then running the cor function on each version of the data set:
## [1] -0.04756589## [1] 0.02795272These results show that \(\boldsymbol{r}=-0.05\) for Height and Hematocrit for males and \(\boldsymbol{r}=0.03\) for females. The first suggests a very weak negative linear relationship and the second suggests a very weak positive linear relationship. The correlation when the two groups were combined (and group information was ignored!) was that \(\boldsymbol{r}=0.37\). So one conclusion here is that correlations on data sets that contain groups can be very misleading (if the groups are ignored). It also emphasizes the importance of exploring for potential subgroups in the data set – these two groups were not obvious in the initial plot, but with added information the real story became clear.
For the Body Fat vs Hematocrit results in Figure 2.107, with an overall correlation of \(\boldsymbol{r}=-0.54\), the subgroup correlations show weaker relationships that also appear to be in different directions (\(\boldsymbol{r}=0.13\) for men and \(\boldsymbol{r}=-0.17\) for women). This doubly reinforces the dangers of aggregating different groups and ignoring the group information.
## [1] 0.1269418## [1] -0.1679751(ref:fig6-8) Scatterplot of athlete’s body fat and hematocrit by sex of athletes. Males were coded as 0s and females as 1s.
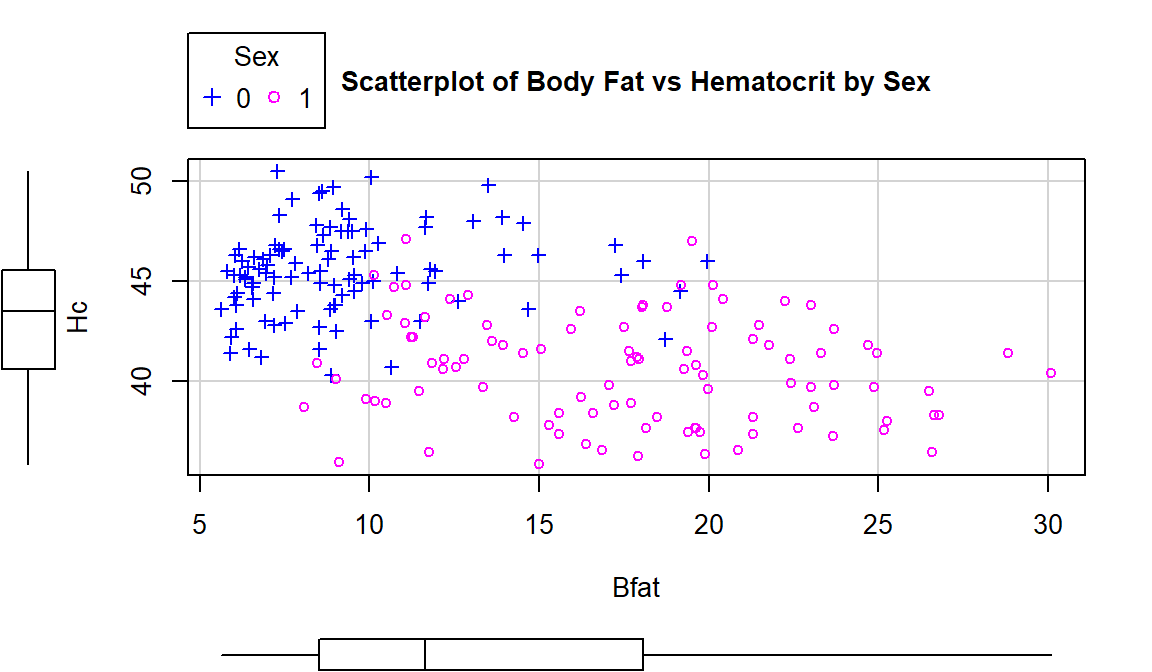
Figure 2.107: (ref:fig6-8)
scatterplot(Hc~Bfat|Sex, data=aisR2, pch=c(3,21), regLine=F, smooth=F,
boxplots="xy", main="Scatterplot of Body Fat vs Hematocrit by Sex")One final exploration for these data involves the body fat and height relationship displayed in Figure 2.108. This relationship shows an even greater disparity between overall and subgroup results. The overall relationship is characterized as a weak negative relationship \((\boldsymbol{r}=-0.20)\) that is not clearly linear or nonlinear. The subgroup relationships are both clearly positive with a stronger relationship for men that might also be nonlinear (for the linear relationships \(\boldsymbol{r}=0.45\) for women and \(\boldsymbol{r}=0.20\) for men). Especially for female athletes, those that are taller seem to have higher body fat percentages. This might be related to the types of sports they compete in – that would be another categorical variable we could incorporate… Both groups also seem to demonstrate slightly more variability in Body Fat associated with taller athletes (each sort of “fans out”).
## [1] 0.1954609## [1] 0.4476962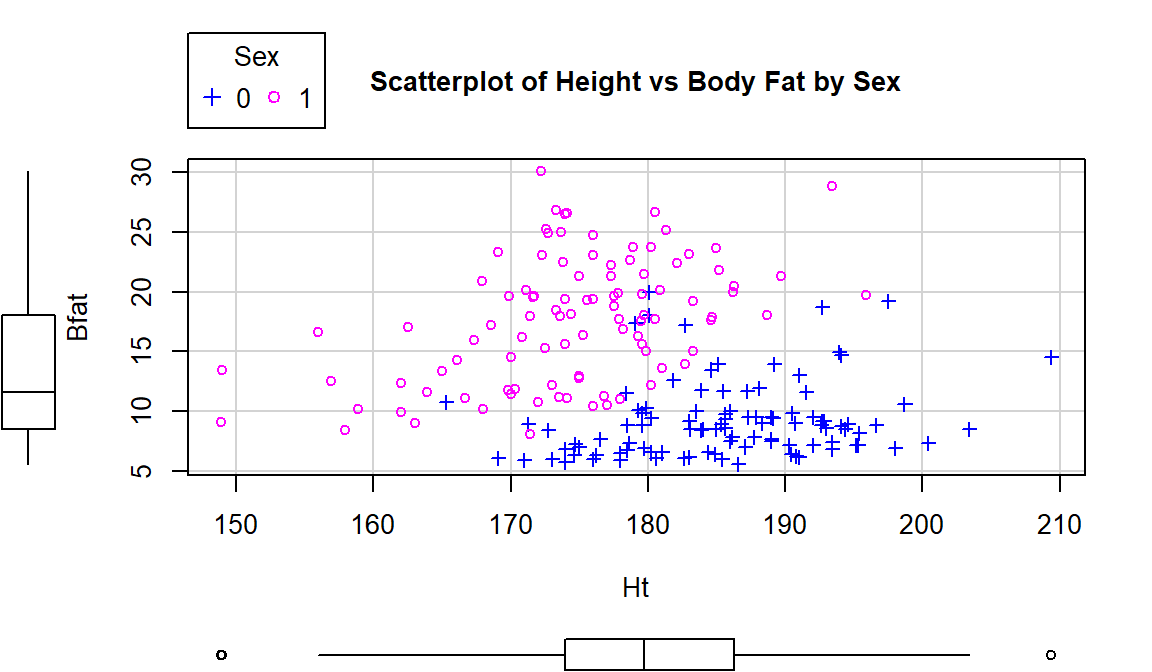
Figure 2.108: Scatterplot of athlete’s body fat and height by sex.
scatterplot(Bfat~Ht|Sex, data=aisR2, pch=c(3,21), regLine=F, smooth=F,
boxplots="xy", main="Scatterplot of Height vs Body Fat by Sex")In each of these situations, the sex of the athletes has the potential to cause misleading conclusions if ignored. There are two ways that this could occur – if we did not measure it then we would have no hope to account for it OR we could have measured it but not adjusted for it in our results, as was done initially. We distinguish between these two situations by defining the impacts of this additional variable as either a confounding or lurking variable:
Confounding variable: affects the response variable and is related to the explanatory variable. The impacts of a confounding variable on the response variable cannot be separated from the impacts of the explanatory variable.
Lurking variable: a potential confounding variable that is not measured and is not considered in the interpretation of the study.
Lurking variables show up in studies sometimes due to lack of knowledge of the system being studied or a lack of resources to measure these variables. Note that there may be no satisfying resolution to the confounding variable problem but that it is better to have measured it and know about it than to have it remain a lurking variable.
To help think about confounding and lurking variables, consider the following situation. On many highways, such as Highway 93 in Montana and north into Canada, recent construction efforts have been involved in creating safe passages for animals by adding fencing and animal crossing structures. These structures both can improve driver safety, save money from costs associated with animal-vehicle collisions, and increase connectivity of animal populations. Researchers (such as Clevenger and Waltho (2005)) involved in these projects are interested in which characteristics of underpasses lead to the most successful structures, mainly measured by rates of animal usage (number of times they cross under the road). Crossing structures are typically made using culverts and those tend to be cylindrical. Researchers are interested in studying the effect of height and width of crossing structures on animal usage. Unfortunately, all the tallest structures are also the widest structures. If animals prefer the tall and wide structures, then there is no way to know if it is due to the height or width of the structure since they are confounded. If the researchers had only measured width, then they might assume that it is the important characteristic of the structures but height could be a lurking variable that really was the factor related to animal usage of the structures. This is an example where it may not be possible to design a study that prevents confounding of the two variables height and width. If the researchers could control the height and width of the structures independently, then they could randomly assign both variables to make sure that some narrow structures are installed that are tall and some that are short. Additionally, they would also want to have some wide structures that are short and some are tall. Careful design of studies can prevent confounding of variables if they are known in advance and it is possible to control them, but in observational studies the observed combinations of variables are uncontrollable. This is why we need to employ additional caution in interpreting results from observational studies. Here that would mean that even if width was found to be a predictor of animal usage, we would likely want to avoid saying that width of the structures caused differences in animal usage.
References
Clevenger, Anthony P, and Nigel Waltho. 2005. “Performance Indices to Identify Attributes of Highway Crossing Structures Facilitating Movement of Large Mammals.” Biological Conservation 121 (3): 453–64.
Fox, John, and Sanford Weisberg. 2011. An R-Companion to Applied Regression, Second Edition. Thousand Oaks, CA: SAGE Publications. http://socserv.socsci.mcmaster.ca/jfox/Books/Companion.
Fox, John, Sanford Weisberg, and Brad Price. 2018. CarData: Companion to Applied Regression Data Sets. https://CRAN.R-project.org/package=carData.
This is related to what is called Simpson’s paradox, where the overall analysis (ignoring a grouping variable) leads to a conclusion of a relationship in one direction, but when the relationship is broken down into subgroups it is in the opposite direction in each group. This emphasizes the importance of checking and accounting for differences in groups and the more complex models we are setting the stage to consider in the coming chapters.↩