- Cover
- Acknowledgments
- 1 Preface
- 2 (R)e-Introduction to statistics
- 2.1 Histograms, boxplots, and density curves
- 2.2 Pirate-plots
- 2.3 Models, hypotheses, and permutations for the two sample mean situation
- 2.4 Permutation testing for the two sample mean situation
- 2.5 Hypothesis testing (general)
- 2.6 Connecting randomization (nonparametric) and parametric tests
- 2.7 Second example of permutation tests
- 2.8 Reproducibility Crisis: Moving beyond p < 0.05, publication bias, and multiple testing issues
- 2.9 Confidence intervals and bootstrapping
- 2.10 Bootstrap confidence intervals for difference in GPAs
- 2.11 Chapter summary
- 2.12 Summary of important R code
- 2.13 Practice problems
- 3 One-Way ANOVA
- 3.1 Situation
- 3.2 Linear model for One-Way ANOVA (cell-means and reference-coding)
- 3.3 One-Way ANOVA Sums of Squares, Mean Squares, and F-test
- 3.4 ANOVA model diagnostics including QQ-plots
- 3.5 Guinea pig tooth growth One-Way ANOVA example
- 3.6 Multiple (pair-wise) comparisons using Tukey’s HSD and the compact letter display
- 3.7 Pair-wise comparisons for the Overtake data
- 3.8 Chapter summary
- 3.9 Summary of important R code
- 3.10 Practice problems
- 4 Two-Way ANOVA
- 4.1 Situation
- 4.2 Designing a two-way experiment and visualizing results
- 4.3 Two-Way ANOVA models and hypothesis tests
- 4.4 Guinea pig tooth growth analysis with Two-Way ANOVA
- 4.5 Observational study example: The Psychology of Debt
- 4.6 Pushing Two-Way ANOVA to the limit: Un-replicated designs and Estimability
- 4.7 Chapter summary
- 4.8 Summary of important R code
- 4.9 Practice problems
- 5 Chi-square tests
- 5.1 Situation, contingency tables, and tableplots
- 5.2 Homogeneity test hypotheses
- 5.3 Independence test hypotheses
- 5.4 Models for R by C tables
- 5.5 Permutation tests for the \(X^2\) statistic
- 5.6 Chi-square distribution for the \(X^2\) statistic
- 5.7 Examining residuals for the source of differences
- 5.8 General protocol for \(X^2\) tests
- 5.9 Political party and voting results: Complete analysis
- 5.10 Is cheating and lying related in students?
- 5.11 Analyzing a stratified random sample of California schools
- 5.12 Chapter summary
- 5.13 Summary of important R commands
- 5.14 Practice problems
- 6 Correlation and Simple Linear Regression
- 6.1 Relationships between two quantitative variables
- 6.2 Estimating the correlation coefficient
- 6.3 Relationships between variables by groups
- 6.4 Inference for the correlation coefficient
- 6.5 Are tree diameters related to tree heights?
- 6.6 Describing relationships with a regression model
- 6.7 Least Squares Estimation
- 6.8 Measuring the strength of regressions: R2
- 6.9 Outliers: leverage and influence
- 6.10 Residual diagnostics – setting the stage for inference
- 6.11 Old Faithful discharge and waiting times
- 6.12 Chapter summary
- 6.13 Summary of important R code
- 6.14 Practice problems
- 7 Simple linear regression inference
- 7.1 Model
- 7.2 Confidence interval and hypothesis tests for the slope and intercept
- 7.3 Bozeman temperature trend
- 7.4 Randomization-based inferences for the slope coefficient
- 7.5 Transformations part I: Linearizing relationships
- 7.6 Transformations part II: Impacts on SLR interpretations: log(y), log(x), & both log(y) & log(x)
- 7.7 Confidence interval for the mean and prediction intervals for a new observation
- 7.8 Chapter summary
- 7.9 Summary of important R code
- 7.10 Practice problems
- 8 Multiple linear regression
- 8.1 Going from SLR to MLR
- 8.2 Validity conditions in MLR
- 8.3 Interpretation of MLR terms
- 8.4 Comparing multiple regression models
- 8.5 General recommendations for MLR interpretations and VIFs
- 8.6 MLR inference: Parameter inferences using the t-distribution
- 8.7 Overall F-test in multiple linear regression
- 8.8 Case study: First year college GPA and SATs
- 8.9 Different intercepts for different groups: MLR with indicator variables
- 8.10 Additive MLR with more than two groups: Headache example
- 8.11 Different slopes and different intercepts
- 8.12 F-tests for MLR models with quantitative and categorical variables and interactions
- 8.13 AICs for model selection
- 8.14 Case study: Forced expiratory volume model selection using AICs
- 8.15 Chapter summary
- 8.16 Summary of important R code
- 8.17 Practice problems
- 9 Case studies
- 9.1 Overview of material covered
- 9.2 The impact of simulated chronic nitrogen deposition on the biomass and N2-fixation activity of two boreal feather moss–cyanobacteria associations
- 9.3 Ants learn to rely on more informative attributes during decision-making
- 9.4 Multi-variate models are essential for understanding vertebrate diversification in deep time
- 9.5 What do didgeridoos really do about sleepiness?
- 9.6 General summary
- References
9.4 Multi-variate models are essential for understanding vertebrate diversification in deep time
Benson and Mannion (2012) published a paleontology study that considered modeling the diversity of Sauropodomorphs across \(n=26\) “stage-level” time bins. Diversity is measured by the count of the number of different species that have been found in a particular level of fossils. Specifically, the counts in the Sauropodomorphs group were obtained for stages between Carnian and Maastrichtian, with the first three stages in the Triassic, the next ten in the Jurassic, and the last eleven in the Cretaceous. They were concerned about variation in sampling efforts and the ability of paleontologists to find fossils across different stages creating a false impression of the changes in biodiversity (counts of species) over time. They first wanted to see if the species counts were related to factors such as the count of dinosaur-bearing-formations (DBF) and the count of dinosaur-bearing-collections (DBC) that have been identified for each period. The thought is that if there are more formations or collections of fossils from certain stages, the diversity might be better counted (more found of those available to find) and those stages with less information available might be under-counted. They also measured the length of each stage (Duration) but did not consider it in their models since they want to reflect the diversity and longer stages would likely have higher diversity.
Their main goal was to develop a model that would control for the effects of sampling efforts and allow them to perform inferences for whether the diversity was different between the Triassic/Jurassic (grouped together) and considered models that included two different versions of sampling effort variables and one for the comparisons of periods (an indicator variable TJK=0 if the observation is in Triassic or Jurassic or 1 if in Cretaceous), which are more explicitly coded below. They log-e transformed all their quantitative variables because the untransformed variables created diagnostic issues including influential points. They explored a model just based on the DBC predictor145 and they analyzed the residuals from that model to see if the biodiversity was different in the Cretaceous or before, finding a “p-value >= 0.0001” (I think they meant < 0.0001146). They were comparing the MLR models you learned to some extended regression models that incorporated a correction for correlation in the responses over time, but we can proceed with fitting some of their MLR models and using an AIC comparison similar to what they used. There are some obvious flaws in their analysis and results that we will avoid147.
First, we start with a plot of the log-diversity vs the log-dinosaur bearing collections by period. We can see fairly strong positive relationships between the log amounts of collections and species found with potentially similar slopes for the two periods but what look like different intercepts. Especially for TJK level 1 (Cretaceous period) observations, we might need to worry about a curving relationship. Note that a similar plot can also be made using the formations version of the quantitative predictor variable and that the research questions involve whether DBF or DBC are better predictor variables.
bm <- read_csv("http://www.math.montana.edu/courses/s217/documents/bensonmanion.csv")
bm2 <- bm[,-c(9:10)]
bm$logSpecies <- log(bm$Species)
bm$logDBCs <- log(bm$DBCs)
bm$logDBFs <- log(bm$DBFs)
bm$TJK <- factor(bm$TJK)
levels(bm$TJK) <- c("Trias_Juras","Cretaceous")
library(car); library(viridis)
scatterplot(logSpecies~logDBCs|TJK, data=bm, smooth=T,
main="Scatterplot of log-diversity vs log-DBCs by period", legend=list(coords="topleft",columns=1), lwd=2, col=viridis(7)[c(5,1)])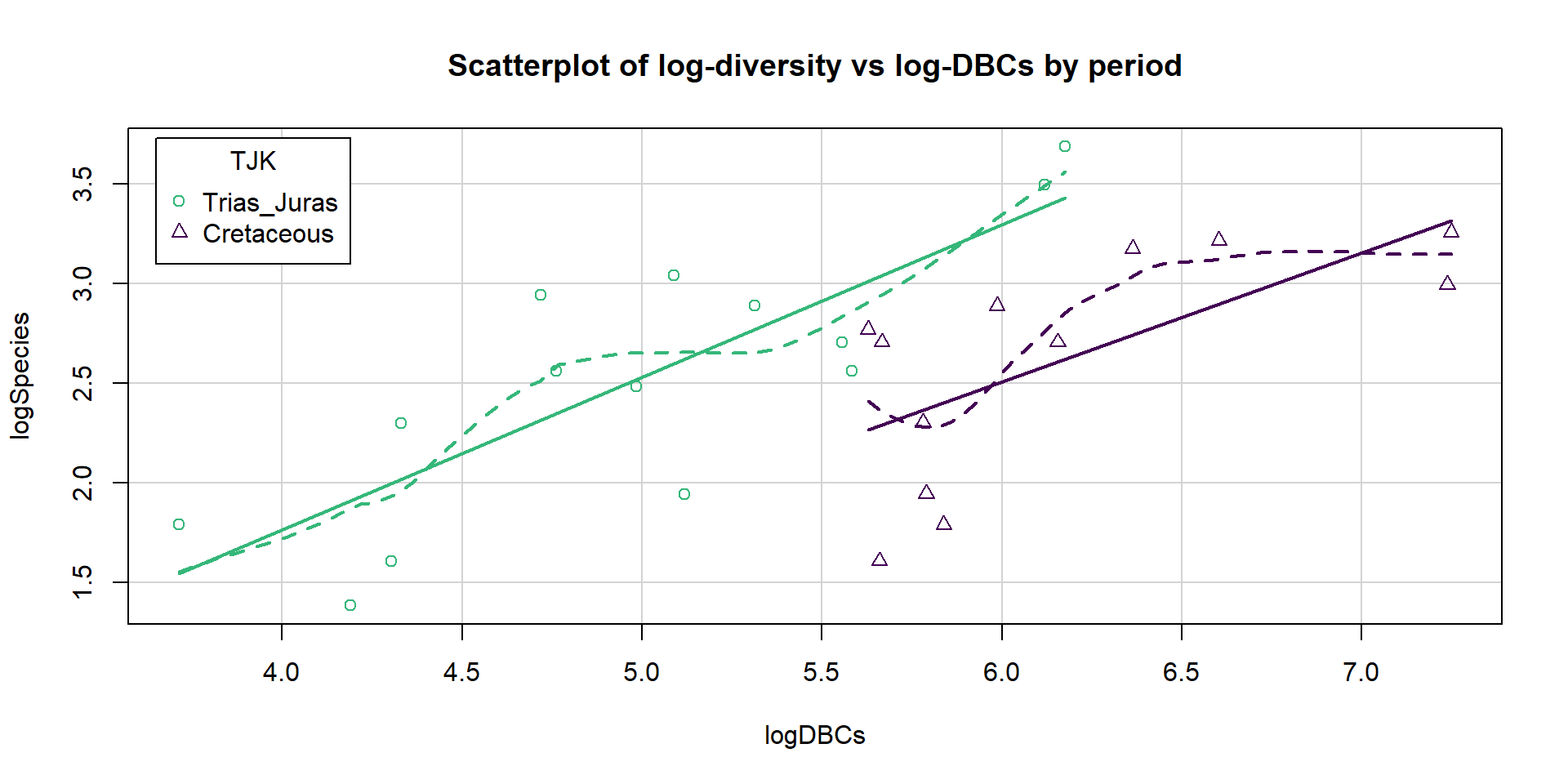
Figure 2.200: Scatterplot of log-biodiversity vs log-DBCs by TJK.
The following results will allow us to explore models similar to theirs. One “full” model they considered is:
\[\log{(\text{count})}_i=\beta_0 + \beta_1\cdot\log{(\text{DBC})}_i + \beta_2I_{\text{TJK},i} + \varepsilon_i\]
which was compared to
\[\log{(\text{count})}_i=\beta_0 + \beta_1\cdot\log{(\text{DBF})}_i + \beta_2I_{\text{TJK},i} + \varepsilon_i\]
as well as the simpler models that each suggests:
\[\begin{array}{rl} \log{(\text{count})}_i &=\beta_0 + \beta_1\cdot\log{(\text{DBC})}_i + \varepsilon_i, \\ \log{(\text{count})}_i &=\beta_0 + \beta_1\cdot\log{(\text{DBF})}_i + \varepsilon_i, \\ \log{(\text{count})}_i &=\beta_0 + \beta_2I_{\text{TJK},i} + \varepsilon_i, \text{ and} \\ \log{(\text{count})}_i &=\beta_0 + \varepsilon_i. \\ \end{array}\]
Both versions of the models (based on DBF or DBC) start with an MLR model with a quantitative variable and two slopes. We can obtain some of the needed model selection results from the first full model using:
bd1 <- lm(logSpecies~logDBCs+TJK, data=bm)
library(MuMIn)
options(na.action = "na.fail")
dredge(bd1, rank="AIC",
extra=c("R^2", adjRsq=function(x) summary(x)$adj.r.squared))## Global model call: lm(formula = logSpecies ~ logDBCs + TJK, data = bm)
## ---
## Model selection table
## (Intrc) lgDBC TJK R^2 adjRsq df logLik AIC delta weight
## 4 -1.0890 0.7243 + 0.580900 0.54440 4 -12.652 33.3 0.00 0.987
## 2 0.1988 0.4283 0.369100 0.34280 3 -17.969 41.9 8.63 0.013
## 1 2.5690 0.000000 0.00000 2 -23.956 51.9 18.61 0.000
## 3 2.5300 + 0.004823 -0.03664 3 -23.893 53.8 20.48 0.000
## Models ranked by AIC(x)And from the second model:
bd2 <- lm(logSpecies~logDBFs+TJK, data=bm)
dredge(bd2, rank="AIC",
extra=c("R^2", adjRsq=function(x) summary(x)$adj.r.squared))## Global model call: lm(formula = logSpecies ~ logDBFs + TJK, data = bm)
## ---
## Model selection table
## (Intrc) lgDBF TJK R^2 adjRsq df logLik AIC delta weight
## 4 -2.4100 1.3710 + 0.519900 0.47810 4 -14.418 36.8 0.00 0.995
## 2 0.5964 0.4882 0.209800 0.17690 3 -20.895 47.8 10.95 0.004
## 1 2.5690 0.000000 0.00000 2 -23.956 51.9 15.08 0.001
## 3 2.5300 + 0.004823 -0.03664 3 -23.893 53.8 16.95 0.000
## Models ranked by AIC(x)The top AIC model is
\(\log{(\text{count})}_i=\beta_0 + \beta_1\cdot\log{(\text{DBC})}_i + \beta_2I_{\text{TJK},i} + \varepsilon_i\)
with an AIC of 33.3. The next best ranked model on AICs was \(\log{(\text{count})}_i=\beta_0 + \beta_1\cdot\log{(\text{DBF})}_i + \beta_2I_{\text{TJK},i} + \varepsilon_i\)
with an AIC of 36.8, so 3.5 AIC units worse than the top model and so there is clear evidence to support the DBC+TJK model over the best version with DBF and all others. We put these
two runs of results together in Table 2.14, re-computing all the
AICs based on the top model from the first full model considered to make it easier to see this.
| Model | R2 | adj R2 | df | logLik | AIC | \(\BD\)AIC |
|---|---|---|---|---|---|---|
| \(\log(\text{count})_i=\beta_0 + \beta_1\cdot\log(\text{DBC})_i + \beta_2I_{\text{TJK},i} + \varepsilon_i\) | 0.5809 | 0.5444 | 4 | -12.652 | 33.3 | 0 |
| \(\log(\text{count})_i=\beta_0 + \beta_1\cdot\log(\text{DBF})_i + \beta_2I_{\text{TJK},i} + \varepsilon_i\) | 0.5199 | 0.4781 | 4 | -14.418 | 36.8 | 3.5 |
| \(\log(\text{count})_i=\beta_0 + \beta_1\cdot\log(\text{DBC})_i + \varepsilon_i\) | 0.3691 | 0.3428 | 3 | -17.969 | 41.9 | 8.6 |
| \(\log(\text{count})_i=\beta_0 + \beta_1\cdot\log(\text{DBF})_i + \varepsilon_i\) | 0.2098 | 0.1769 | 3 | -20.895 | 47.8 | 14.5 |
| \(\log(\text{count})_i=\beta_0 + \varepsilon_i\) | 0 | 0 | 2 | -23.956 | 51.9 | 18.6 |
| \(\log(\text{count})_i=\beta_0 + \beta_2I_{\text{TJK},i} + \varepsilon_i\) | 0.0048 | -0.0366 | 3 | -23.893 | 53.8 | 20.5 |
Table 2.14 suggests some interesting results. By itself, \(TJK\) leads to the worst performing model on the AIC measure, ranking below a model with nothing in it (mean-only) and 20.5 AIC units worse than the top model. But the two top models distinctly benefit from the inclusion of TJK. This suggests that after controlling for the sampling effort, either through DBC or DBF, the differences in the stages captured by TJK can be more clearly observed.
So the top model in our (correct) results148 suggests that log(DBC) is important as well as different intercepts for the two periods. We can interrogate this model further but we should check the diagnostics (Figure 2.201) and consider our model assumptions first as AICs are not valid if the model assumptions are clearly violated.
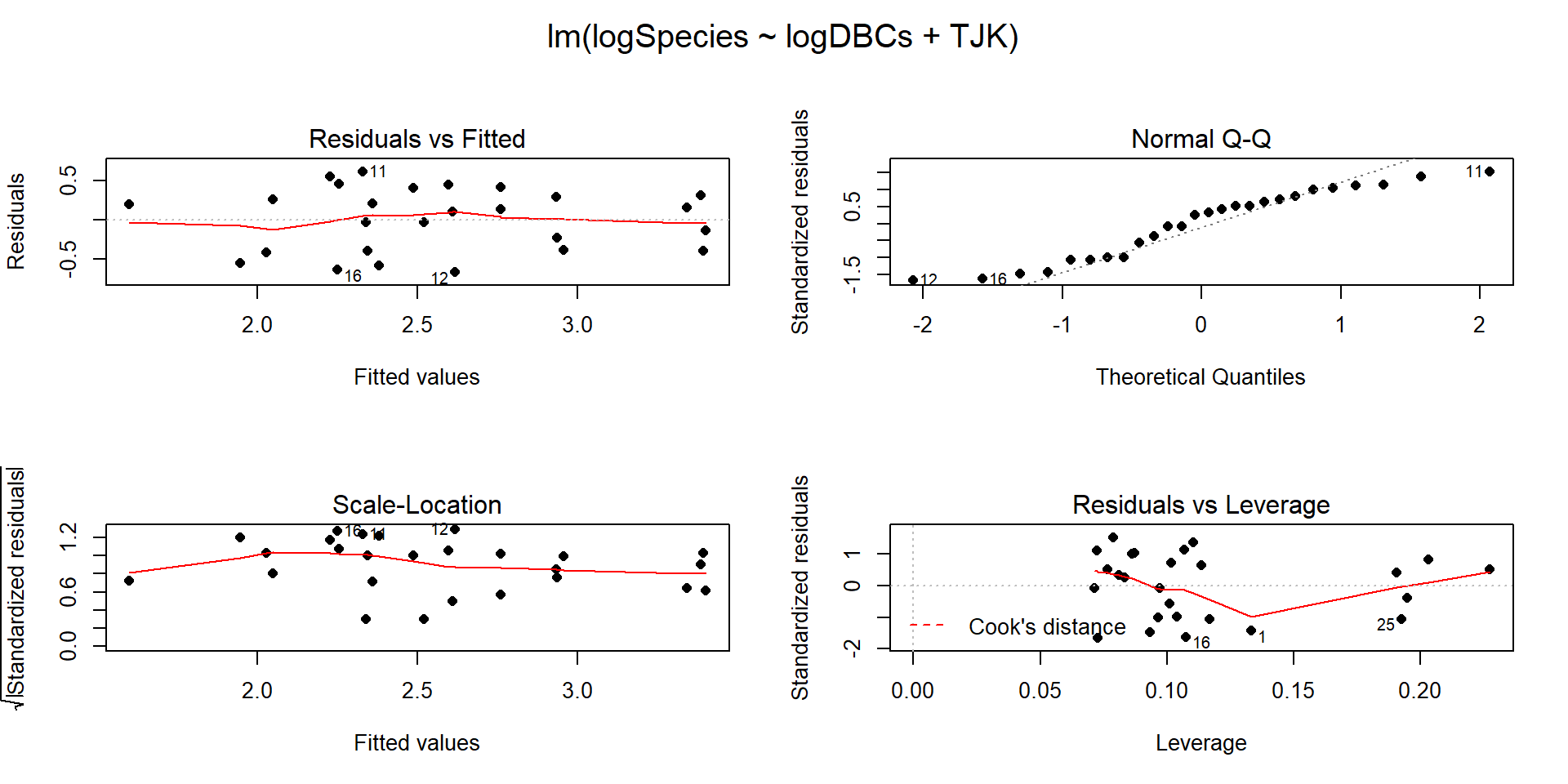
Figure 2.201: Diagnostic plots for the top AIC model.
The constant variance, linearity, and assessment of influence do not suggest any problems with those assumptions. This is reinforced in the partial residuals in Figure 2.202. The normality assumption is possibly violated but shows lighter tails than expected from a normal distribution and so should cause few problems with inferences (we would be looking for an answer of “yes, there is a violation of the normality assumption but that problem is minor because the pattern is not the problematic type of violation because both the upper and lower tails are shorter than expected from a normal distribution”). The other assumption that is violated for all our models is that the observations are independent. Between neighboring stages in time, there would likely be some sort of relationship in the biodiversity so we should not assume that the observations are independent (this is another time series of observations). The authors acknowledged this issue but unskillfully attempted to deal with it. Because an interaction was not considered in any of the models, there also is an assumption that the results are parallel enough for the two groups. The scatterplot in Figure 2.200 suggests that using parallel lines for the two groups is probably reasonable but a full assessment really should also explore that fully to verify that there is no support for an interaction which would relate to different impacts of sampling efforts on the response across the levels of TJK.
Ignoring the violation of the independence assumption, we are otherwise OK to explore the model more and see what it tells us about biodiversity of Sauropodomorphs. The top model is estimated to be \(\log{(\widehat{\text{count}})}_i=-1.089 + 0.724\cdot\log{(\text{DBC})}_i -0.75I_{\text{TJK},i}\). This suggests that for the early observations (TJK=Trias_Juras), the model is \(\log{(\widehat{\text{count}})}_i=-1.089 + 0.724\cdot\log{(\text{DBC})}_i\) and for the Cretaceous period (TJK=Cretaceous), the model is \(\log{(\widehat{\text{count}})}_i=-1.089 + -0.75+0.724\cdot\log{(\text{DBC})}_i\) which simplifies to \(\log{(\widehat{\text{count}})}_i=-1.84 + 0.724\cdot\log{(\text{DBC})}_i\). This suggests that the sampling efforts have the same impacts on all observations and having an increase in logDBCs is associated with increases in the mean log-biodiversity. Specifically, for a 1 log-count increase in the log-DBCs, we estimate, on average, to have a 0.724 log-count change in the mean log-biodiversity, after accounting for different intercepts for the two periods considered. We could also translate this to the original count scale but will leave it as is, because their real question of interest involves the differences between the periods. The change in the y-intercepts of -0.76 suggests that the Cretaceous has a lower average log-biodiversity by 0.75 log-count, after controlling for the log-sampling effort. This suggests that the Cretaceous had a lower corrected mean log-Sauropodomorph biodiversity \(\require{enclose} (t_{23}=-3.41;\enclose{horizontalstrike}{\text{p-value}=0.0024})\) than the combined results for the Triassic and Jurassic. On the original count scale, this suggests \(\exp(-0.76)=0.47\) times (53% drop in) the median biodiversity count per stage for Cretaceous versus the prior time period, after correcting for log-sampling effort in each stage.
##
## Call:
## lm(formula = logSpecies ~ logDBCs + TJK, data = bm)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.6721 -0.3955 0.1149 0.2999 0.6158
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -1.0887 0.6533 -1.666 0.1092
## logDBCs 0.7243 0.1288 5.622 1.01e-05
## TJKCretaceous -0.7598 0.2229 -3.409 0.0024
##
## Residual standard error: 0.4185 on 23 degrees of freedom
## Multiple R-squared: 0.5809, Adjusted R-squared: 0.5444
## F-statistic: 15.94 on 2 and 23 DF, p-value: 4.54e-05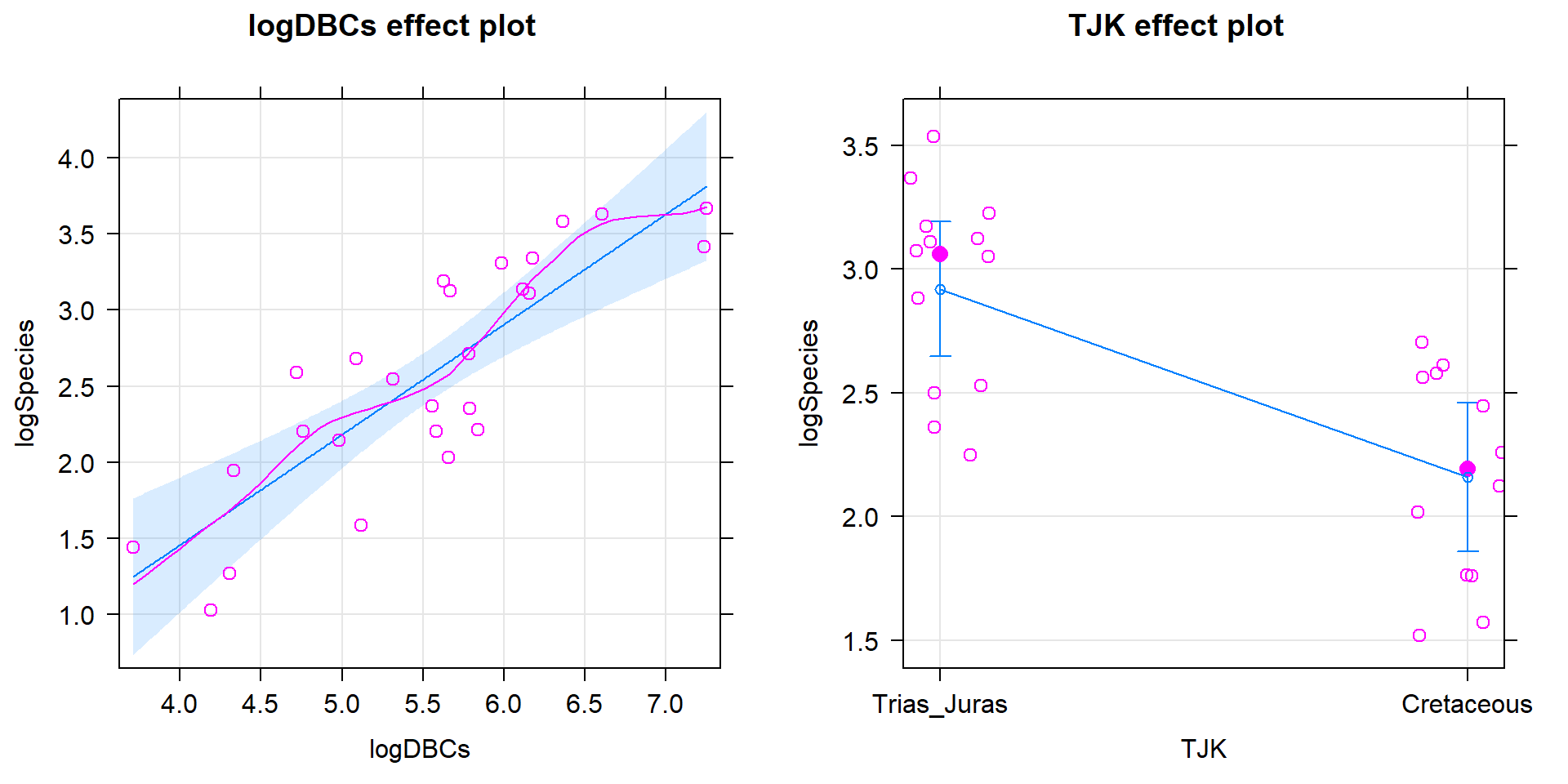
Figure 2.202: Term-plots for the top AIC model with partial residuals.
Their study shows some interesting contrasts between methods. They tried to use AIC-based model selection methods across all the models but then used p-values to really make their final conclusions. This presents a philosophical inconsistency that bothers some more than others but should bother everyone. One thought is whether they needed to use AICs at all since they wanted to use p-values? The one reason they might have preferred to use AICs is that it allows the direct comparison of
\[\log{(\text{count})}_i=\beta_0 + \beta_1\log{(\text{DBC})}_i + \beta_2I_{\text{TJK},i} + \varepsilon_i\]
to
\[\log{(\text{count})}_i=\beta_0 + \beta_1\cdot\log{(\text{DBF})}_i + \beta_2I_{\text{TJK},i} + \varepsilon_i,\]
exploring whether DBC or DBF is “better” with TJK in the model. There is no hypothesis test to compare these two models because one is not nested in the other – it is not possible to get from one model to the other by setting one or more slope coefficients to 0 so we can’t hypothesis test our way from one model to the other one. The AICs suggest strong support for the model with DBC and TJK as compared to the model with DBF and TJK, so that helps us make that decision. After that step, we could rely on \(t\)-tests or ANOVA \(F\)-tests to decide whether further refinement is suggested/possible for the model with DBC and TJK. This would provide the direct inferences that they probably want and are trying to obtain from AICs along with p-values in their paper.
Finally, their results would actually be more valid if they had used a set of statistical methods designed for modeling responses that are counts of events or things, especially those whose measurements change as a function of sampling effort; models called Poisson rate models would be ideal for their application which are also special cases of the generalized linear models noted in the extensions for modeling categorical responses. The other aspect of the biodiversity that they measured for each stage was the duration of the stage. They never incorporated that information and it makes sense given their interests in comparing biodiversity across stages, not understanding why more or less biodiversity might occur. But other researchers might want to estimate the biodiversity after also controlling for the length of time that the stage lasted and the sampling efforts involved in detecting the biodiversity of each stage, models that are only a few steps away from those considered here. In general, this paper presents some of the pitfalls of attempting to use advanced statistical methods as well as hinting at the benefits. The statistical models are the only way to access the results of interest; inaccurate usage of statistical models can provide inaccurate conclusions. They seemed to mostly get the right answers despite a suite of errors in their work.
References
Benson, Roger B. J., and Philip D. Mannion. 2012. “Multi-Variate Models Are Essential for Understanding Vertebrate Diversification in Deep Time.” Biology Letters 8: 127–30. https://doi.org/10.1098/rsbl.2011.0460.
This was not even close to their top AIC model so they made an odd choice.↩
I had students read this paper in a class and one decided that this was a reasonable way to report small p-values – it is WRONG. We are interested in how small a p-value might be and saying it is over a value is never useful, especially if you say it is larger than a tiny number.↩
All too often, I read journal articles that have under-utilized, under-reported, mis-applied, or mis-interpreted statistical methods and results. One of the reasons that I wanted to write this book was to help more people move from basic statistical knowledge to correct use of intermediate statistical methods and beginning to see the potential in more advanced statistical methods. It took me many years of being a statistician (after getting a PhD) just to feel armed for battle when confronted with new applications and two stat courses are not enough to get you there, but you have to start somewhere. You are only maybe two or three hundred hours into your 10,000 hours required for mastery. This book is intended get you some solid fundamentals to build on or a few intermediate tools to use if this is your last statistics training experience.↩
They also had an error in their AIC results that is difficult to explain here but was due to an un-careful usage of the results from the more advanced models that account for autocorrelation, which seems to provide the proper ranking of models (that they ignored) but did not provide the correct differences among models.↩