- Cover
- Acknowledgments
- 1 Preface
- 2 (R)e-Introduction to statistics
- 2.1 Histograms, boxplots, and density curves
- 2.2 Pirate-plots
- 2.3 Models, hypotheses, and permutations for the two sample mean situation
- 2.4 Permutation testing for the two sample mean situation
- 2.5 Hypothesis testing (general)
- 2.6 Connecting randomization (nonparametric) and parametric tests
- 2.7 Second example of permutation tests
- 2.8 Reproducibility Crisis: Moving beyond p < 0.05, publication bias, and multiple testing issues
- 2.9 Confidence intervals and bootstrapping
- 2.10 Bootstrap confidence intervals for difference in GPAs
- 2.11 Chapter summary
- 2.12 Summary of important R code
- 2.13 Practice problems
- 3 One-Way ANOVA
- 3.1 Situation
- 3.2 Linear model for One-Way ANOVA (cell-means and reference-coding)
- 3.3 One-Way ANOVA Sums of Squares, Mean Squares, and F-test
- 3.4 ANOVA model diagnostics including QQ-plots
- 3.5 Guinea pig tooth growth One-Way ANOVA example
- 3.6 Multiple (pair-wise) comparisons using Tukey’s HSD and the compact letter display
- 3.7 Pair-wise comparisons for the Overtake data
- 3.8 Chapter summary
- 3.9 Summary of important R code
- 3.10 Practice problems
- 4 Two-Way ANOVA
- 4.1 Situation
- 4.2 Designing a two-way experiment and visualizing results
- 4.3 Two-Way ANOVA models and hypothesis tests
- 4.4 Guinea pig tooth growth analysis with Two-Way ANOVA
- 4.5 Observational study example: The Psychology of Debt
- 4.6 Pushing Two-Way ANOVA to the limit: Un-replicated designs and Estimability
- 4.7 Chapter summary
- 4.8 Summary of important R code
- 4.9 Practice problems
- 5 Chi-square tests
- 5.1 Situation, contingency tables, and tableplots
- 5.2 Homogeneity test hypotheses
- 5.3 Independence test hypotheses
- 5.4 Models for R by C tables
- 5.5 Permutation tests for the \(X^2\) statistic
- 5.6 Chi-square distribution for the \(X^2\) statistic
- 5.7 Examining residuals for the source of differences
- 5.8 General protocol for \(X^2\) tests
- 5.9 Political party and voting results: Complete analysis
- 5.10 Is cheating and lying related in students?
- 5.11 Analyzing a stratified random sample of California schools
- 5.12 Chapter summary
- 5.13 Summary of important R commands
- 5.14 Practice problems
- 6 Correlation and Simple Linear Regression
- 6.1 Relationships between two quantitative variables
- 6.2 Estimating the correlation coefficient
- 6.3 Relationships between variables by groups
- 6.4 Inference for the correlation coefficient
- 6.5 Are tree diameters related to tree heights?
- 6.6 Describing relationships with a regression model
- 6.7 Least Squares Estimation
- 6.8 Measuring the strength of regressions: R2
- 6.9 Outliers: leverage and influence
- 6.10 Residual diagnostics – setting the stage for inference
- 6.11 Old Faithful discharge and waiting times
- 6.12 Chapter summary
- 6.13 Summary of important R code
- 6.14 Practice problems
- 7 Simple linear regression inference
- 7.1 Model
- 7.2 Confidence interval and hypothesis tests for the slope and intercept
- 7.3 Bozeman temperature trend
- 7.4 Randomization-based inferences for the slope coefficient
- 7.5 Transformations part I: Linearizing relationships
- 7.6 Transformations part II: Impacts on SLR interpretations: log(y), log(x), & both log(y) & log(x)
- 7.7 Confidence interval for the mean and prediction intervals for a new observation
- 7.8 Chapter summary
- 7.9 Summary of important R code
- 7.10 Practice problems
- 8 Multiple linear regression
- 8.1 Going from SLR to MLR
- 8.2 Validity conditions in MLR
- 8.3 Interpretation of MLR terms
- 8.4 Comparing multiple regression models
- 8.5 General recommendations for MLR interpretations and VIFs
- 8.6 MLR inference: Parameter inferences using the t-distribution
- 8.7 Overall F-test in multiple linear regression
- 8.8 Case study: First year college GPA and SATs
- 8.9 Different intercepts for different groups: MLR with indicator variables
- 8.10 Additive MLR with more than two groups: Headache example
- 8.11 Different slopes and different intercepts
- 8.12 F-tests for MLR models with quantitative and categorical variables and interactions
- 8.13 AICs for model selection
- 8.14 Case study: Forced expiratory volume model selection using AICs
- 8.15 Chapter summary
- 8.16 Summary of important R code
- 8.17 Practice problems
- 9 Case studies
- 9.1 Overview of material covered
- 9.2 The impact of simulated chronic nitrogen deposition on the biomass and N2-fixation activity of two boreal feather moss–cyanobacteria associations
- 9.3 Ants learn to rely on more informative attributes during decision-making
- 9.4 Multi-variate models are essential for understanding vertebrate diversification in deep time
- 9.5 What do didgeridoos really do about sleepiness?
- 9.6 General summary
- References
8.12 F-tests for MLR models with quantitative and categorical variables and interactions
For models with multi-category \((J>2)\) categorical variables we need a method for deciding if all the extra complexity present in the additive or interaction models is necessary. We can appeal to model selection methods such as the adjusted R2 that focus on balancing model fit and complexity but interests often move to trying to decide if the differences are more extreme than we would expect by chance if there were no group differences in intercepts or slopes. Because of the multi-degree of freedom aspects of the use of indicator variables (\(J-1\) variables for a \(J\) level categorical variable), we have to develop tests that combine and assess information across multiple “variables” – even though these indicators all pertain to a single original categorical variable. ANOVA \(F\)-tests did exactly this sort of thing in the One and Two-Way ANOVA models and can do that for us here. There are two models that we perform tests in – the additive and the interaction models. We start with a discussion of the tests in an interaction setting since that provides us the first test to consider in most situations to assess evidence of whether the extra complexity of varying slopes is really needed. If we don’t “need” the varying slopes or if the plot really does have lines for the groups that look relatively parallel, we can fit the additive model and either assess evidence of the need for different intercepts or for the quantitative predictor – either is a reasonable next step. Basically this establishes a set of nested models (each model is a reduced version of another more complicated model higher in the tree of models and we can move down the tree by setting a set of slope coefficients to 0) displayed in Figure 2.185. This is based on the assumption that we would proceed through the model, dropping terms if the p-values are large (“not significant” in the diagram) to arrive at a final model.
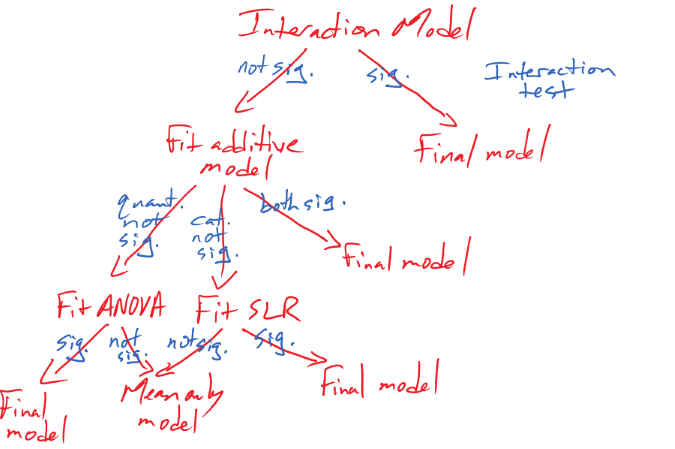
Figure 2.185: Diagram of models to consider in an interaction model.
If the initial interaction test suggests the interaction is important, then no further refinement should be considered and that model should be explored (this was the same protocol suggested in the 2-WAY ANOVA situation, the other place where we considered interactions). If the interaction is not deemed important based on the test, then the model should be re-fit using both variables in an additive model. In that additive model, both variables can be assessed conditional on the other one. If both have small p-values, then that is the final model and should be explored further. If either the categorical or quantitative variable have large p-values, then they can be dropped from the model and the model re-fit with only one variable in it, usually starting with dropping the component with the largest p-value if both are not “small”. Note that if there is only a categorical variable remaining, then we would call that linear model a One-Way ANOVA (quantitative response and \(J\) group categorical explanatory) and if the only remaining variable is quantitative, then a SLR model is being fit. If that final variable has a large p-value in either model, it can be removed and all that is left to describe the responses is a mean-only model. Otherwise the single variable model is the final model. Usually we will not have to delve deeply into this tree of models and might stop earlier in the tree if that fully addresses our research question, but it is good to consider the potential paths that an analysis could involve before it is started if model refinement is being considered.
To perform the first test (after checking that assumptions are not problematic, of
course),
we can apply the Anova function from the car package to an interaction
model135.
It will provide three tests, one for each variable by themselves, which are not
too interesting, and then the interaction test. This will result in an
\(F\)-statistic that, if the assumptions are true, will follow an
\(F(J-1, n-2J)\)-distribution
under the null hypothesis. This tests
the hypotheses:
\(\boldsymbol{H_0:}\) The slope for \(\boldsymbol{x}\) is the same for all \(\boldsymbol{J}\) groups in the population vs
\(\boldsymbol{H_A:}\) The slope for \(\boldsymbol{x}\) in at least one group differs from the others in the population.
This test is also legitimate in the case of a two-level categorical variable \((J=2)\) and then follows an \(F(1, n-4)\)-distribution under the null hypothesis. With \(J=2\), the p-value from this test matches the results for the \(t\)-test \((t_{n-4})\) for the single slope-changing coefficient in the model summary output. The noise tolerance study, introduced in Section 8.10, provides a situation for exploring the results in detail.
With the \(J=4\) level categorical variable (Treatment), the model for the second noise tolerance measurement (du2) as a function of the interaction between Treatment and initial noise tolerance (du1) is
\[\begin{array}{rl} \text{du2}_i = \beta_0 &+ \beta_1\cdot\text{du1}_i + \beta_2I_{T1,i} + \beta_3I_{T2,i} + \beta_4I_{T3,i} \\ &+ \beta_5I_{T1,i}\cdot\text{du1}_i + \beta_6I_{T2,i}\cdot\text{du1}_i + \beta_7I_{T3,i}\cdot\text{du1}_i+\varepsilon_i. \end{array}\]
We can re-write the previous hypotheses in one of two more specific ways:
\(H_0:\) The slope for du1 is the same for all four Treatment groups in the population OR
\(H_0: \beta_5=\beta_6=\beta_7=0\)
- This defines a null hypothesis that all the deviation coefficients for getting different slopes for the different treatments are 0 in the population.
\(H_A:\) The slope for du1 is NOT the same for all four Treatment groups in the population (at least one group has a different slope) OR
\(H_A:\) At least one of \(\beta_5,\beta_6,\beta_7\) is different from 0 in the population.
- The alternative states that at least one of the deviation coefficients for getting different slopes for the different Treatments is not 0 in the population.
In this situation, the results for the test of these hypotheses is in the row
labeled du1:treatment in the Anova output. The ANOVA table below shows
a test statistic of \(F=0.768\) with the numerator df of 3, coming from \(J-1\),
and the denominator df of 90, coming from \(n-2J=98-2*4=90\) and also provided
in the Residuals row in the table, leading to an \(F(3, 90)\)-distribution
for the test statistic under the null hypothesis.
The p-value from this
distribution is 0.515, showing little to no evidence against
the null hypothesis, so does not suggest that the slope coefficient for du1 in explaining du2 is different for
at least one of the Treatment groups in the population.
## Anova Table (Type II tests)
##
## Response: du2
## Sum Sq Df F value Pr(>F)
## du1 1197.78 1 259.5908 <2e-16
## treatment 23.90 3 1.7265 0.1672
## du1:treatment 10.63 3 0.7679 0.5150
## Residuals 415.27 90Without evidence to support using an interaction, we should consider both the quantitative and categorical variables in an additive model. The ANOVA table for the additive model contains two interesting tests. One test is for the quantitative variable discussed previously. The other is for the categorical variable, assessing whether different y-intercepts are needed. The additive model here is
\[\text{du2}_i = \beta_0 + \beta_1\cdot\text{du1}_i + \beta_2I_{T1,i} + \beta_3I_{T2,i} + \beta_4I_{T3,i} +\varepsilon_i.\ \]
The hypotheses assessed in the ANOVA test for treatment are:
\(H_0:\) The y-intercept for the model with du1 is the same for all four Treatment groups in the population OR
\(H_0: \beta_2=\beta_3=\beta_4=0\)
- This defines a null hypothesis that all the deviation coefficients for getting different y-intercepts for the different Treatments are 0 in the population.
\(H_A:\) The y-intercepts for the model with du1 is NOT the same for all four Treatment groups in the population (at least one group has a different y-intercept) OR
\(H_A:\) At least one of \(\beta_2,\beta_3,\beta_4\) is different from 0 in the population.
- The alternative states that at least one of the deviation coefficients for getting different y-intercepts for the different Treatments is not 0 in the population.
The \(F\)-test for the categorical variable in an additive model follows \(F(J-1, n-J-1)\)-distribution under the null hypothesis. For this example, the test statistic for Treatment follows an \(F(3, 93)\)-distribution under the null hypothesis. The observed test statistic has a value of 1.74, generating a p-value of 0.164. So we would find weak evidence against the null hypothesis and so does not suggest some difference in y-intercepts between the treatment groups, in a model with du1, in the population. We could interpret this in the fashion we used initially in MLR by stating this result as: there is little evidence against the null hypothesis of no difference in the mean du2 for the Treatment groups after controlling for du1.
## Anova Table (Type II tests)
##
## Response: du2
## Sum Sq Df F value Pr(>F)
## du1 1197.8 1 261.5491 <2e-16
## treatment 23.9 3 1.7395 0.1643
## Residuals 425.9 93In the same ANOVA table, there is a test for the du1 model component. This tests \(H_0: \beta_1=0\) vs \(H_A: \beta_1\ne 0\) in a model with different y-intercepts for the different treatment groups. If we remove this term from the model, all we are left with is different y-intercepts for the groups. A model just with different y-intercepts is typically called a One-Way ANOVA model. Here, there it appears that the quantitative variable is needed in the model after controlling for the different y-intercepts for different treatments since it has a small p-value (\(F\)(1,93)=261.55 or \(t\)(93)=16.172, p-value<0.0001). Note that this interpretation retains the conditional wording regardless of whether the other variable had a small p-value or it did not. If you want an unconditional interpretation for a variable, then you will need to refit the model without the other variable(s) after deciding that they are not important.
We could also use the
anovafunction to do this but usingAnovathroughout this material provides the answers we want in the additive model and it has no impact for the only test of interest in the interaction model since the interaction is the last component in the model.↩