- Cover
- Acknowledgments
- 1 Preface
- 2 (R)e-Introduction to statistics
- 2.1 Histograms, boxplots, and density curves
- 2.2 Pirate-plots
- 2.3 Models, hypotheses, and permutations for the two sample mean situation
- 2.4 Permutation testing for the two sample mean situation
- 2.5 Hypothesis testing (general)
- 2.6 Connecting randomization (nonparametric) and parametric tests
- 2.7 Second example of permutation tests
- 2.8 Reproducibility Crisis: Moving beyond p < 0.05, publication bias, and multiple testing issues
- 2.9 Confidence intervals and bootstrapping
- 2.10 Bootstrap confidence intervals for difference in GPAs
- 2.11 Chapter summary
- 2.12 Summary of important R code
- 2.13 Practice problems
- 3 One-Way ANOVA
- 3.1 Situation
- 3.2 Linear model for One-Way ANOVA (cell-means and reference-coding)
- 3.3 One-Way ANOVA Sums of Squares, Mean Squares, and F-test
- 3.4 ANOVA model diagnostics including QQ-plots
- 3.5 Guinea pig tooth growth One-Way ANOVA example
- 3.6 Multiple (pair-wise) comparisons using Tukey’s HSD and the compact letter display
- 3.7 Pair-wise comparisons for the Overtake data
- 3.8 Chapter summary
- 3.9 Summary of important R code
- 3.10 Practice problems
- 4 Two-Way ANOVA
- 4.1 Situation
- 4.2 Designing a two-way experiment and visualizing results
- 4.3 Two-Way ANOVA models and hypothesis tests
- 4.4 Guinea pig tooth growth analysis with Two-Way ANOVA
- 4.5 Observational study example: The Psychology of Debt
- 4.6 Pushing Two-Way ANOVA to the limit: Un-replicated designs and Estimability
- 4.7 Chapter summary
- 4.8 Summary of important R code
- 4.9 Practice problems
- 5 Chi-square tests
- 5.1 Situation, contingency tables, and tableplots
- 5.2 Homogeneity test hypotheses
- 5.3 Independence test hypotheses
- 5.4 Models for R by C tables
- 5.5 Permutation tests for the \(X^2\) statistic
- 5.6 Chi-square distribution for the \(X^2\) statistic
- 5.7 Examining residuals for the source of differences
- 5.8 General protocol for \(X^2\) tests
- 5.9 Political party and voting results: Complete analysis
- 5.10 Is cheating and lying related in students?
- 5.11 Analyzing a stratified random sample of California schools
- 5.12 Chapter summary
- 5.13 Summary of important R commands
- 5.14 Practice problems
- 6 Correlation and Simple Linear Regression
- 6.1 Relationships between two quantitative variables
- 6.2 Estimating the correlation coefficient
- 6.3 Relationships between variables by groups
- 6.4 Inference for the correlation coefficient
- 6.5 Are tree diameters related to tree heights?
- 6.6 Describing relationships with a regression model
- 6.7 Least Squares Estimation
- 6.8 Measuring the strength of regressions: R2
- 6.9 Outliers: leverage and influence
- 6.10 Residual diagnostics – setting the stage for inference
- 6.11 Old Faithful discharge and waiting times
- 6.12 Chapter summary
- 6.13 Summary of important R code
- 6.14 Practice problems
- 7 Simple linear regression inference
- 7.1 Model
- 7.2 Confidence interval and hypothesis tests for the slope and intercept
- 7.3 Bozeman temperature trend
- 7.4 Randomization-based inferences for the slope coefficient
- 7.5 Transformations part I: Linearizing relationships
- 7.6 Transformations part II: Impacts on SLR interpretations: log(y), log(x), & both log(y) & log(x)
- 7.7 Confidence interval for the mean and prediction intervals for a new observation
- 7.8 Chapter summary
- 7.9 Summary of important R code
- 7.10 Practice problems
- 8 Multiple linear regression
- 8.1 Going from SLR to MLR
- 8.2 Validity conditions in MLR
- 8.3 Interpretation of MLR terms
- 8.4 Comparing multiple regression models
- 8.5 General recommendations for MLR interpretations and VIFs
- 8.6 MLR inference: Parameter inferences using the t-distribution
- 8.7 Overall F-test in multiple linear regression
- 8.8 Case study: First year college GPA and SATs
- 8.9 Different intercepts for different groups: MLR with indicator variables
- 8.10 Additive MLR with more than two groups: Headache example
- 8.11 Different slopes and different intercepts
- 8.12 F-tests for MLR models with quantitative and categorical variables and interactions
- 8.13 AICs for model selection
- 8.14 Case study: Forced expiratory volume model selection using AICs
- 8.15 Chapter summary
- 8.16 Summary of important R code
- 8.17 Practice problems
- 9 Case studies
- 9.1 Overview of material covered
- 9.2 The impact of simulated chronic nitrogen deposition on the biomass and N2-fixation activity of two boreal feather moss–cyanobacteria associations
- 9.3 Ants learn to rely on more informative attributes during decision-making
- 9.4 Multi-variate models are essential for understanding vertebrate diversification in deep time
- 9.5 What do didgeridoos really do about sleepiness?
- 9.6 General summary
- References
8.5 General recommendations for MLR interpretations and VIFs
There are some important issues to remember122 when interpreting regression models that can result in common mistakes.
Don’t claim to “hold everything constant” for a single individual:
Mathematically this is a correct interpretation of the MLR model but it is rarely the case that we could have this occur in real applications. Is it possible to increase the Elevation while holding the Max.Temp constant? We discussed making term-plots doing exactly this – holding the other variables constant at their means. If we interpret each slope coefficient in an MLR conditionally then we can craft interpretations such as: For locations that have a Max.Temp of, say, \(45^\circ F\) and Min.Temp of, say, \(30^\circ F\), a 1 foot increase in Elevation tends to be associated with a 0.0268 inch increase in Snow Depth on average. This does not try to imply that we can actually make that sort of change but that given those other variables, the change for that variable is a certain magnitude.
Don’t interpret the regression results causally (or casually?)…
Unless you are analyzing the results of a designed experiment (where the levels of the explanatory variable(s) were randomly assigned) you cannot state that a change in that \(x\) causes a change in \(y\), especially for a given individual. The multicollinearity in predictors makes it especially difficult to put too much emphasis on a single slope coefficient because it may be corrupted/modified by the other variables being in the model. In observational studies, there are also all the potential lurking variables that we did not measure or even confounding variables that we did measure but can’t disentangle from the variable used in a particular model. While we do have a complicated mathematical model relating various \(x\text{'s}\) to the response, do not lose that fundamental focus on causal vs non-causal inferences based on the design of the study.
Be cautious about doing prediction in MLR – you might be doing extrapolation!
It is harder to know if you are doing extrapolation in MLR since you could be in a region of the \(x\text{'s}\) that no observations were obtained. Suppose we want to predict the Snow Depth for an Elevation of 6000 and Max.Temp of 30. Is this extrapolation based on Figure 2.161? In other words, can you find any observations “nearby” in the plot of the two variables together? What about an Elevation of 6000 and a Max.Temp of 40? The first prediction is in a different proximity to observations than the second one… In situations with more than two explanatory variables it becomes even more challenging to know whether you are doing extrapolation and the problem grows as the number of dimensions to search increases… In fact, in complicated MLR models we typically do not know whether there are observations “nearby” if we are doing predictions for unobserved combinations of our predictors. Note that Figure 2.161 also reinforces our potential collinearity problem between Elevation and Max.Temp with higher elevations being strongly associated with lower temperatures.
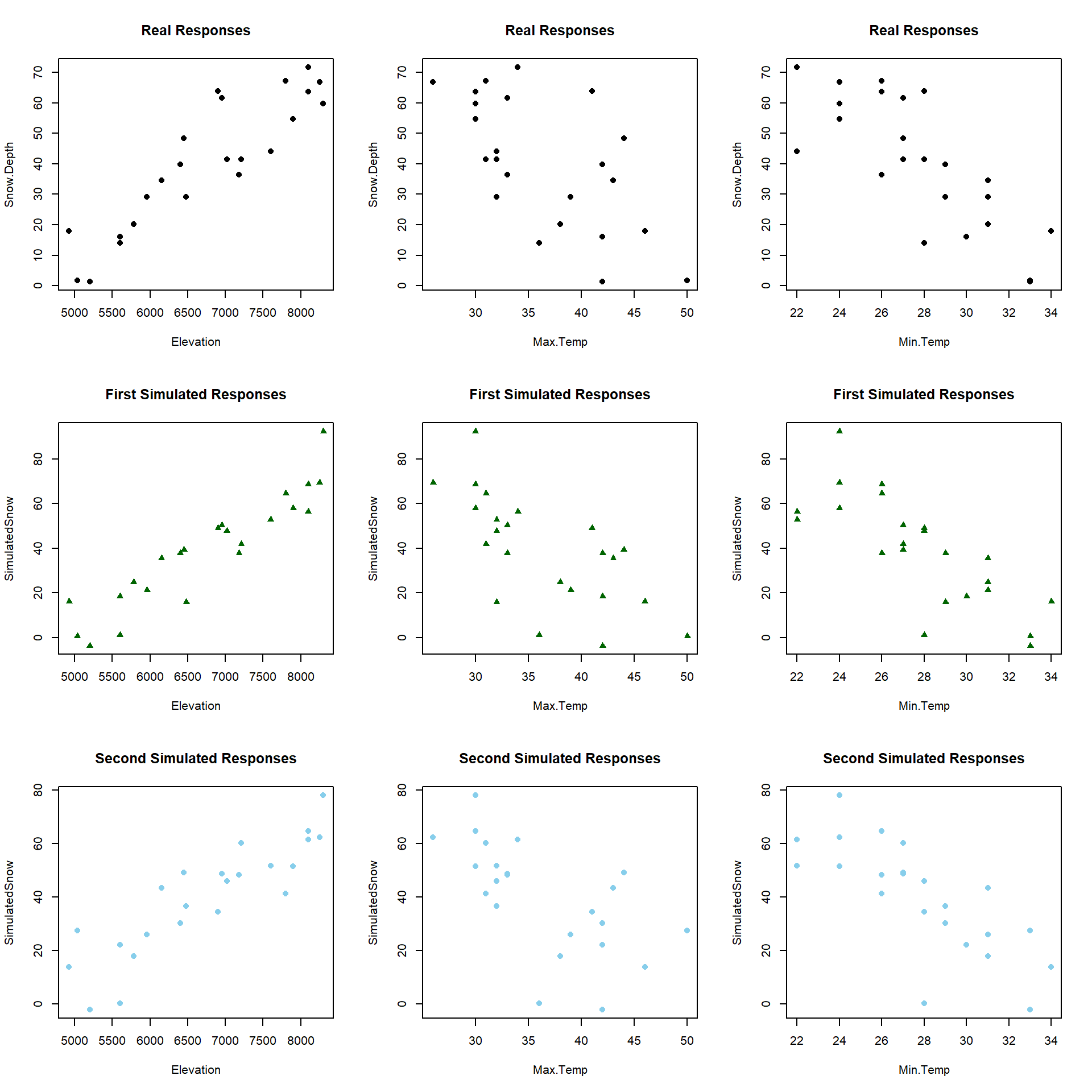
Figure 2.161: Scatterplot of observed Elevations and Maximum Temperatures for SNOTEL data.
Don’t think that the sign of a coefficient is special…
Adding other variables into the MLR models can cause a switch in the coefficients or change their magnitude or make them go from “important” to “unimportant” without changing the slope too much. This is related to the conditionality of the relationships being estimated in MLR and the potential for sharing of information in the predictors when it is present.
Multicollinearity in MLR models:
When explanatory variables are not independent (related) to one another, then including/excluding one variable will have an impact on the other variable. Consider the correlations among the predictors in the SNOTEL data set or visually displayed in Figure 2.162:
library(corrplot) par(mfrow=c(1,1), oma=c(0,0,1,0)) corrplot.mixed(cor(snotel2[-c(9,22),3:6]), upper.col=c(1, "orange"), lower.col=c(1, "orange")) round(cor(snotel2[-c(9,22),3:6]),2)
Figure 2.162: Plot of correlation matrix in the snow depth data set with influential points removed
## Max.Temp Min.Temp Elevation Snow.Depth ## Max.Temp 1.00 0.77 -0.84 -0.64 ## Min.Temp 0.77 1.00 -0.91 -0.79 ## Elevation -0.84 -0.91 1.00 0.90 ## Snow.Depth -0.64 -0.79 0.90 1.00The predictors all share at least moderately strong linear relationships. For example, the \(\boldsymbol{r}=-0.91\) between Min.Temp and Elevation suggests that they contain very similar information and that extends to other pairs of variables as well. When variables share information, their addition to models may not improve the performance of the model and actually can make the estimated coefficients unstable, creating uncertainty in the correct coefficients because of the shared information. It seems that Elevation is related to Snow Depth but maybe it is because it has lower Minimum Temperatures? So you might wonder how we can find the “correct” slopes when they are sharing information in the response variable. The short answer is that we can’t. But we do use Least Squares to find coefficient estimates as we did before – except that we have to remember that these estimates are conditional on other variables in the model for our interpretation since they impact one another within the model. It ends up that the uncertainty of pinning those variables down in the presence of shared information leads to larger SEs for all the slopes. And that we can actually measure how much each of the SEs are inflated because of multicollinearity with other variables in the model using what are called Variance Inflation Factors (or VIFs).
VIFs provide a way to assess the multicollinearity in the MLR model that
is caused by including specific variables. The amount of information that is
shared between a single explanatory variable and the others can be found by
regressing that variable on the others and calculating R2
for that model. The code for this regression is something like:
lm(X1~X2+X3+...+XK), which regresses X1on X2 through XK.
The
\(1-\boldsymbol{R}^2\) from this regression is the amount of independent
information in X1 that is not explained by (or related to) the other variables in the model.
The VIF for each variable is defined using this quantity as
\(\textbf{VIF}_{\boldsymbol{k}}\boldsymbol{=1/(1-R^2_k)}\) for variable \(k\).
If there is no shared information \((\boldsymbol{R}^2=0)\), then the VIF will be
1. But if the information is completely shared with other variables
\((\boldsymbol{R}^2=1)\), then the VIF goes to infinity (1/0). Basically, large
VIFs are bad, with the rule of thumb that values over 5 or 10 are considered
“large” values indicating high or extreme multicollinearity in the model for that particular
variable. We use this scale to determine if multicollinearity is a definite problem for a
variable of interest. But any value of the VIF over 1 indicates some amount of multicollinearity is present. Additionally, the \(\boldsymbol{\sqrt{\textbf{VIF}_k}}\) is
also very interesting as it is the number of times larger than the SE for the
slope for variable \(k\) is due to collinearity with other variables in the model.
This is the most useful scale to understand VIFs and allows you to make your own assessment of whether you think the multicollinearity is “important” based on how inflated the SEs are in a particular situation. An example will show how to easily get these results
and where the results come from.
In general, the easy way to obtain VIFs is using the vif function from the
car package (Fox, Weisberg, and Price (2018), Fox (2003)).
It has the advantage of also providing a reasonable
result when we include categorical variables in models
(Sections 8.9 and 8.11) over some other sources of this information in R. We apply the vif
function directly to a model of interest and it generates values for each explanatory variable.
## Elevation Min.Temp Max.Temp
## 8.164201 5.995301 3.350914Not surprisingly, there is an indication of extreme problems with multicollinearity in two of the three variables in the model with the largest issues identified for Elevation and Min.Temp. Both of their VIFs exceed 5 indicating large multicollinearity problems. On the square-root scale, the VIFs show more interpretation utility.
## Elevation Min.Temp Max.Temp
## 2.857307 2.448530 1.830550The result for Elevation of 2.86 suggests that the SE for Elevation is 2.86 times larger than it should be because of multicollinearity with other variables in the model. Similarly, the Min.Temp SE is 2.45 times larger and the Max.Temp SE is 1.83 times larger. Even the result for Max.Temp suggests an issue with multicollinearity even though it is below the cut-off for noting extreme issues with shared information. All of this generally suggests issues with multicollinearity in the model and that we need to be cautious in interpreting any slope coefficients from this model because they are all being impacted by shared information in the predictor variables.
In order to see how the VIF is calculated for Elevation, we need to regress Elevation on Min.Temp and Max.Temp. Note that this model is only fit to find the percentage of variation in elevation explained by the temperature variables. It ends up being 0.8775 – so a high percentage of Elevation can be explained by the linear model using min and max temperatures.
##
## Call:
## lm(formula = Elevation ~ Min.Temp + Max.Temp, data = snotel2[-c(9,
## 22), ])
##
## Residuals:
## Min 1Q Median 3Q Max
## -1120.05 -142.99 14.45 186.73 624.61
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 14593.21 699.77 20.854 4.85e-15
## Min.Temp -208.82 38.94 -5.363 3.00e-05
## Max.Temp -56.28 20.90 -2.693 0.014
##
## Residual standard error: 395.2 on 20 degrees of freedom
## Multiple R-squared: 0.8775, Adjusted R-squared: 0.8653
## F-statistic: 71.64 on 2 and 20 DF, p-value: 7.601e-10Using this result, we can calculate
\[\text{VIF}_{\text{elevation}} = \dfrac{1}{1-R^2_{\text{elevation}}} = \dfrac{1}{1-0.8775} = \dfrac{1}{0.1225} = 8.16\]
## [1] 0.1225## [1] 8.163265Note that when we observe small VIFs (close to 1), that provides us with confidence that multicollinearity is not causing problems under the surface of a particular MLR model. Also note that we can’t use the VIFs to do anything about multicollinearity in the models – it is just a diagnostic to understand the magnitude of the problem.
References
Fox, John. 2003. “Effect Displays in R for Generalised Linear Models.” Journal of Statistical Software 8 (15): 1–27. http://www.jstatsoft.org/v08/i15/.
Fox, John, Sanford Weisberg, and Brad Price. 2018. CarData: Companion to Applied Regression Data Sets. https://CRAN.R-project.org/package=carData.