- Cover
- Acknowledgments
- 1 Preface
- 2 (R)e-Introduction to statistics
- 2.1 Histograms, boxplots, and density curves
- 2.2 Pirate-plots
- 2.3 Models, hypotheses, and permutations for the two sample mean situation
- 2.4 Permutation testing for the two sample mean situation
- 2.5 Hypothesis testing (general)
- 2.6 Connecting randomization (nonparametric) and parametric tests
- 2.7 Second example of permutation tests
- 2.8 Reproducibility Crisis: Moving beyond p < 0.05, publication bias, and multiple testing issues
- 2.9 Confidence intervals and bootstrapping
- 2.10 Bootstrap confidence intervals for difference in GPAs
- 2.11 Chapter summary
- 2.12 Summary of important R code
- 2.13 Practice problems
- 3 One-Way ANOVA
- 3.1 Situation
- 3.2 Linear model for One-Way ANOVA (cell-means and reference-coding)
- 3.3 One-Way ANOVA Sums of Squares, Mean Squares, and F-test
- 3.4 ANOVA model diagnostics including QQ-plots
- 3.5 Guinea pig tooth growth One-Way ANOVA example
- 3.6 Multiple (pair-wise) comparisons using Tukey’s HSD and the compact letter display
- 3.7 Pair-wise comparisons for the Overtake data
- 3.8 Chapter summary
- 3.9 Summary of important R code
- 3.10 Practice problems
- 4 Two-Way ANOVA
- 4.1 Situation
- 4.2 Designing a two-way experiment and visualizing results
- 4.3 Two-Way ANOVA models and hypothesis tests
- 4.4 Guinea pig tooth growth analysis with Two-Way ANOVA
- 4.5 Observational study example: The Psychology of Debt
- 4.6 Pushing Two-Way ANOVA to the limit: Un-replicated designs and Estimability
- 4.7 Chapter summary
- 4.8 Summary of important R code
- 4.9 Practice problems
- 5 Chi-square tests
- 5.1 Situation, contingency tables, and tableplots
- 5.2 Homogeneity test hypotheses
- 5.3 Independence test hypotheses
- 5.4 Models for R by C tables
- 5.5 Permutation tests for the \(X^2\) statistic
- 5.6 Chi-square distribution for the \(X^2\) statistic
- 5.7 Examining residuals for the source of differences
- 5.8 General protocol for \(X^2\) tests
- 5.9 Political party and voting results: Complete analysis
- 5.10 Is cheating and lying related in students?
- 5.11 Analyzing a stratified random sample of California schools
- 5.12 Chapter summary
- 5.13 Summary of important R commands
- 5.14 Practice problems
- 6 Correlation and Simple Linear Regression
- 6.1 Relationships between two quantitative variables
- 6.2 Estimating the correlation coefficient
- 6.3 Relationships between variables by groups
- 6.4 Inference for the correlation coefficient
- 6.5 Are tree diameters related to tree heights?
- 6.6 Describing relationships with a regression model
- 6.7 Least Squares Estimation
- 6.8 Measuring the strength of regressions: R2
- 6.9 Outliers: leverage and influence
- 6.10 Residual diagnostics – setting the stage for inference
- 6.11 Old Faithful discharge and waiting times
- 6.12 Chapter summary
- 6.13 Summary of important R code
- 6.14 Practice problems
- 7 Simple linear regression inference
- 7.1 Model
- 7.2 Confidence interval and hypothesis tests for the slope and intercept
- 7.3 Bozeman temperature trend
- 7.4 Randomization-based inferences for the slope coefficient
- 7.5 Transformations part I: Linearizing relationships
- 7.6 Transformations part II: Impacts on SLR interpretations: log(y), log(x), & both log(y) & log(x)
- 7.7 Confidence interval for the mean and prediction intervals for a new observation
- 7.8 Chapter summary
- 7.9 Summary of important R code
- 7.10 Practice problems
- 8 Multiple linear regression
- 8.1 Going from SLR to MLR
- 8.2 Validity conditions in MLR
- 8.3 Interpretation of MLR terms
- 8.4 Comparing multiple regression models
- 8.5 General recommendations for MLR interpretations and VIFs
- 8.6 MLR inference: Parameter inferences using the t-distribution
- 8.7 Overall F-test in multiple linear regression
- 8.8 Case study: First year college GPA and SATs
- 8.9 Different intercepts for different groups: MLR with indicator variables
- 8.10 Additive MLR with more than two groups: Headache example
- 8.11 Different slopes and different intercepts
- 8.12 F-tests for MLR models with quantitative and categorical variables and interactions
- 8.13 AICs for model selection
- 8.14 Case study: Forced expiratory volume model selection using AICs
- 8.15 Chapter summary
- 8.16 Summary of important R code
- 8.17 Practice problems
- 9 Case studies
- 9.1 Overview of material covered
- 9.2 The impact of simulated chronic nitrogen deposition on the biomass and N2-fixation activity of two boreal feather moss–cyanobacteria associations
- 9.3 Ants learn to rely on more informative attributes during decision-making
- 9.4 Multi-variate models are essential for understanding vertebrate diversification in deep time
- 9.5 What do didgeridoos really do about sleepiness?
- 9.6 General summary
- References
5.6 Chi-square distribution for the \(X^2\) statistic
When one additional assumption beyond the previous assumptions for
the permutation
test is met, it is possible to avoid permutations to find the distribution of
the \(X^2\) statistic under the null hypothesis and get a p-value using
what is called the Chi-square or \(\boldsymbol{\chi^2}\)-distribution.
The name of our test statistic, X-squared, is meant to allude to the
potential that this will follow a \(\boldsymbol{\chi^2}\)-distribution
in certain situations but may not do that all the time and we still
can use the methods in Section 5.5. Along with the
previous assumption
regarding independence and all expected cell counts are greater than 0, we make a
requirement that N (the total sample size) is “large enough” and
this assumption is written in terms of the expected cell counts.
If N is large, then all the expected cell counts should also be
large because all those observations have
to go somewhere. The problems for the \(\boldsymbol{\chi^2}\)-distribution
as an approximation to the distribution
of the \(X^2\) statistic under the null hypothesis come when expected
cell counts are below 5. And the smaller the expected cell counts become, the
more problematic the \(\boldsymbol{\chi^2}\)-distribution is as an
approximation of the sampling distribution of the \(X^2\) statistic under
the null hypothesis. The standard rule of thumb is that all the expected
cell counts need to exceed 5 for the parametric approach to be valid.
When
this condition is violated, it is better to use the permutation approach.
The chisq.test function will provide a warning message
to help you notice this. But it is good practice to always explore
the expected cell counts using chisq.test(...)$expected.
## Improved
## Treatment None Some Marked
## Placebo 21.5 7.166667 14.33333
## Treated 20.5 6.833333 13.66667In the Arthritis data set, the sample size was sufficiently large for the \(\boldsymbol{\chi^2}\)-distribution to provide an accurate p-value since the smallest expected cell count is 6.833 (so all expected counts are larger than 5).
The \(\boldsymbol{\chi^2}\)-distribution is a right-skewed distribution that starts at 0 as shown in Figure 2.81. Its shape changes as a function of its degrees of freedom. In the contingency table analyses, the degrees of freedom for the Chi-square test are calculated as
\[\textbf{DF} \mathbf{=(R-1)*(C-1)} = (\text{number of rows }-1)* (\text{number of columns }-1).\]
In the \(2 \times 3\) table above, the \(\text{DF}=(2-1)*(3-1)=2\) leading
to a Chi-square
distribution with 2 df for the distribution of \(X^2\) under the null
hypothesis. The p-value is based on the area to the right of the observed
\(X^2\) value of 13.055 and the pchisq function provides that area as
0.00146.
Note that this is very similar to the permutation result found
previously for these data.
## [1] 0.001462658We’ll see more examples of the \(\boldsymbol{\chi^2}\)-distributions in each of the examples that follow.
(ref:fig5-10) \(\boldsymbol{\chi^2}\)-distribution with two degrees of freedom with the observed statistic of 13.1 indicated with a vertical line.
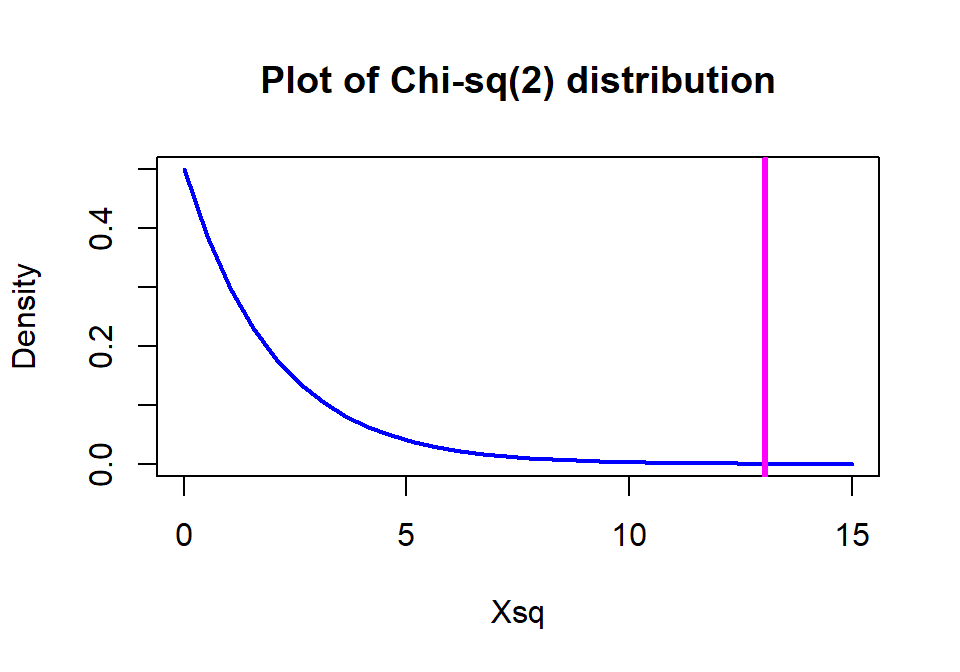
Figure 2.81: (ref:fig5-10)
A small side note about sample sizes is warranted here. In contingency tables, especially those based on survey data, it is common to have large overall sample sizes (\(N\)). With large sample sizes, it becomes easy to find strong evidence against the null hypothesis, even when the “distance” from the null is relatively minor and possibly unimportant. By this we mean that the observed proportions are a small practical distance from the situation described in the null. After obtaining a small p-value, we need to consider whether we have obtained practical significance (or maybe better described as practical importance) to accompany our discussion of strong evidence against the null hypothesis. Whether a result is large enough to be of practical importance can only be judged by knowing something about the situation we are studying and by providing a good summary of our results to allow experts to assess the size and importance of the result. Unfortunately, many researchers are so happy to see small p-values that this is their last step. We encountered a similar situation in the car overtake distance data set where a large sample size provided a data set that had a small p-value and possibly minor differences in the means driving it.
If we revisit our observed results, re-plotted in Figure 2.82 since Figure 2.73 is many pages earlier, knowing that we have strong evidence against the null hypothesis of no difference between Placebo and Treated groups, what can we say about the effectiveness of the arthritis medication? It seems that there is a real and important increase in the proportion of patients getting improvement (Some or Marked). If the differences “looked” smaller, even with a small p-value you87 might not recommend someone take the drug…
(ref:fig5-11) Stacked bar chart of the Arthritis data comparing Treated and Placebo.
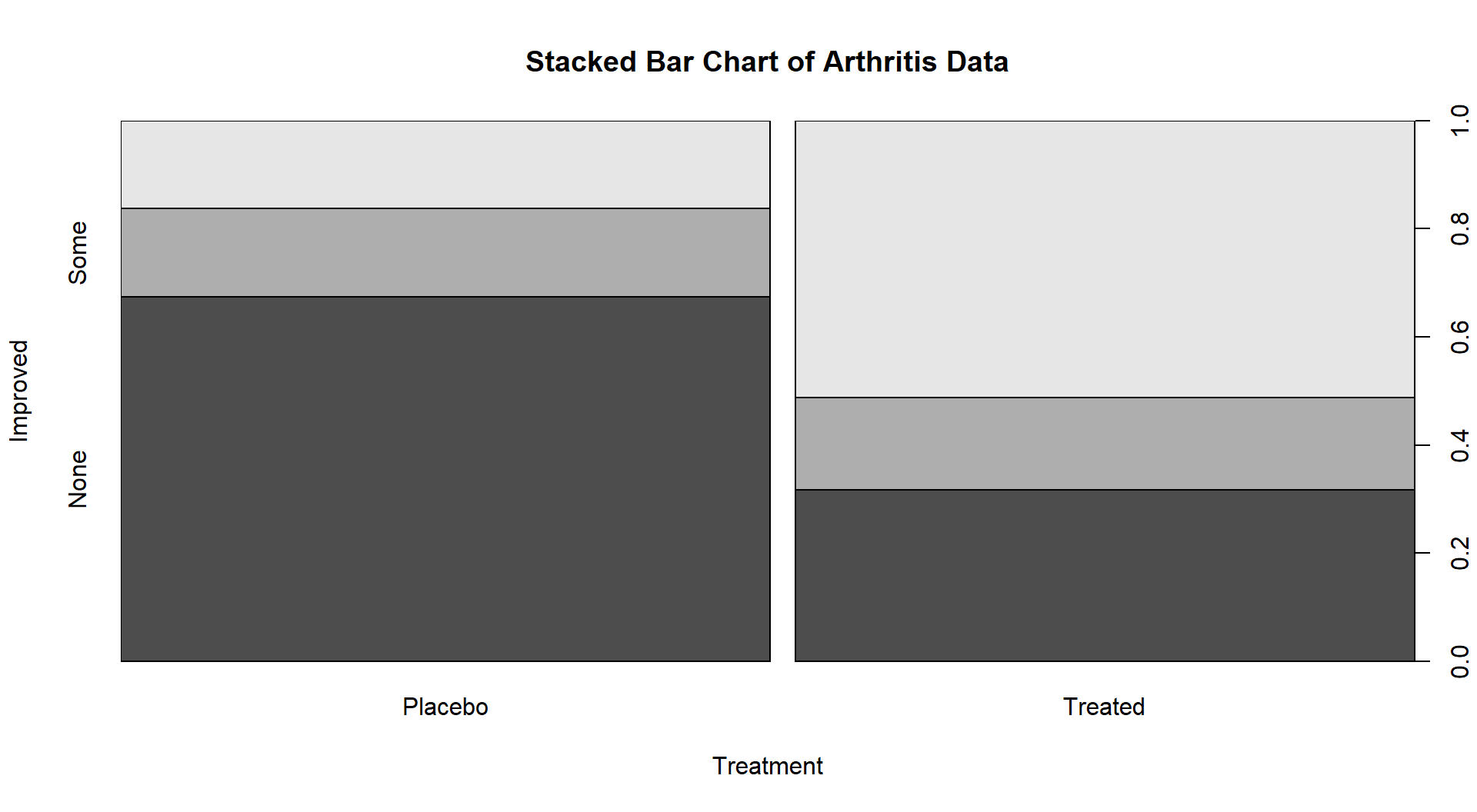
Figure 2.82: (ref:fig5-11)
Doctors are faced with this exact dilemma – with little more training than you have now in statistics, they read a result like this in a paper and used to be encouraged to focus on the p-value to decide about treatment recommendations. Would you recommend the treatment here just based on the small p-value? Would having Figure 2.82 to go with the small p-value help you make a more educated decision? Now the recommendations are starting to move past just focusing on the p-values and thinking about the practical importance and size of the differences. The potential benefits of a treatment need to be balanced with risks of complications too, but that takes us back into discussing having multiple analyses in the same study (treatment improvement, complications/not, etc.).↩