- Cover
- Acknowledgments
- 1 Preface
- 2 (R)e-Introduction to statistics
- 2.1 Histograms, boxplots, and density curves
- 2.2 Pirate-plots
- 2.3 Models, hypotheses, and permutations for the two sample mean situation
- 2.4 Permutation testing for the two sample mean situation
- 2.5 Hypothesis testing (general)
- 2.6 Connecting randomization (nonparametric) and parametric tests
- 2.7 Second example of permutation tests
- 2.8 Reproducibility Crisis: Moving beyond p < 0.05, publication bias, and multiple testing issues
- 2.9 Confidence intervals and bootstrapping
- 2.10 Bootstrap confidence intervals for difference in GPAs
- 2.11 Chapter summary
- 2.12 Summary of important R code
- 2.13 Practice problems
- 3 One-Way ANOVA
- 3.1 Situation
- 3.2 Linear model for One-Way ANOVA (cell-means and reference-coding)
- 3.3 One-Way ANOVA Sums of Squares, Mean Squares, and F-test
- 3.4 ANOVA model diagnostics including QQ-plots
- 3.5 Guinea pig tooth growth One-Way ANOVA example
- 3.6 Multiple (pair-wise) comparisons using Tukey’s HSD and the compact letter display
- 3.7 Pair-wise comparisons for the Overtake data
- 3.8 Chapter summary
- 3.9 Summary of important R code
- 3.10 Practice problems
- 4 Two-Way ANOVA
- 4.1 Situation
- 4.2 Designing a two-way experiment and visualizing results
- 4.3 Two-Way ANOVA models and hypothesis tests
- 4.4 Guinea pig tooth growth analysis with Two-Way ANOVA
- 4.5 Observational study example: The Psychology of Debt
- 4.6 Pushing Two-Way ANOVA to the limit: Un-replicated designs and Estimability
- 4.7 Chapter summary
- 4.8 Summary of important R code
- 4.9 Practice problems
- 5 Chi-square tests
- 5.1 Situation, contingency tables, and tableplots
- 5.2 Homogeneity test hypotheses
- 5.3 Independence test hypotheses
- 5.4 Models for R by C tables
- 5.5 Permutation tests for the \(X^2\) statistic
- 5.6 Chi-square distribution for the \(X^2\) statistic
- 5.7 Examining residuals for the source of differences
- 5.8 General protocol for \(X^2\) tests
- 5.9 Political party and voting results: Complete analysis
- 5.10 Is cheating and lying related in students?
- 5.11 Analyzing a stratified random sample of California schools
- 5.12 Chapter summary
- 5.13 Summary of important R commands
- 5.14 Practice problems
- 6 Correlation and Simple Linear Regression
- 6.1 Relationships between two quantitative variables
- 6.2 Estimating the correlation coefficient
- 6.3 Relationships between variables by groups
- 6.4 Inference for the correlation coefficient
- 6.5 Are tree diameters related to tree heights?
- 6.6 Describing relationships with a regression model
- 6.7 Least Squares Estimation
- 6.8 Measuring the strength of regressions: R2
- 6.9 Outliers: leverage and influence
- 6.10 Residual diagnostics – setting the stage for inference
- 6.11 Old Faithful discharge and waiting times
- 6.12 Chapter summary
- 6.13 Summary of important R code
- 6.14 Practice problems
- 7 Simple linear regression inference
- 7.1 Model
- 7.2 Confidence interval and hypothesis tests for the slope and intercept
- 7.3 Bozeman temperature trend
- 7.4 Randomization-based inferences for the slope coefficient
- 7.5 Transformations part I: Linearizing relationships
- 7.6 Transformations part II: Impacts on SLR interpretations: log(y), log(x), & both log(y) & log(x)
- 7.7 Confidence interval for the mean and prediction intervals for a new observation
- 7.8 Chapter summary
- 7.9 Summary of important R code
- 7.10 Practice problems
- 8 Multiple linear regression
- 8.1 Going from SLR to MLR
- 8.2 Validity conditions in MLR
- 8.3 Interpretation of MLR terms
- 8.4 Comparing multiple regression models
- 8.5 General recommendations for MLR interpretations and VIFs
- 8.6 MLR inference: Parameter inferences using the t-distribution
- 8.7 Overall F-test in multiple linear regression
- 8.8 Case study: First year college GPA and SATs
- 8.9 Different intercepts for different groups: MLR with indicator variables
- 8.10 Additive MLR with more than two groups: Headache example
- 8.11 Different slopes and different intercepts
- 8.12 F-tests for MLR models with quantitative and categorical variables and interactions
- 8.13 AICs for model selection
- 8.14 Case study: Forced expiratory volume model selection using AICs
- 8.15 Chapter summary
- 8.16 Summary of important R code
- 8.17 Practice problems
- 9 Case studies
- 9.1 Overview of material covered
- 9.2 The impact of simulated chronic nitrogen deposition on the biomass and N2-fixation activity of two boreal feather moss–cyanobacteria associations
- 9.3 Ants learn to rely on more informative attributes during decision-making
- 9.4 Multi-variate models are essential for understanding vertebrate diversification in deep time
- 9.5 What do didgeridoos really do about sleepiness?
- 9.6 General summary
- References
4.2 Designing a two-way experiment and visualizing results
Ideally, we want to randomly assign the levels of each factor so that we can attribute causality to any detected effects and to reduce the chances of confounding, where the differences we think are due to one explanatory variable might be due to another variable that varied with the this explanatory variable of interest. Because there are two factors, we would need to design a random assignment scheme to select the levels of both variables. For example, we could randomly select a brand and then randomly select the number of drops to apply from the levels chosen for each measurement. Or we could decide on how many observations we want at each combination of the two factors (ideally having them all equal so the design is balanced) and then randomize the order of applying the different combinations of levels.
Why might it be important to randomly apply the brand and number of drops in an experiment? There are situations where the order of observations can be related to changes in the responses and we want to be able to eliminate the order of observations from being related to the levels of the factors – otherwise the order of observations and levels of the factors would be confounded. For example, suppose that the area where the experiment is being performed becomes wet over time and the later measurements have extra water that gets onto the paper towels and they tend to fail more quickly. If all the observations for the second brand were done later in the study, then the order of observations impacts could make the second brand look worse. If the order of measurements to be made is randomized, then even if there is some drift in the responses over the order of observations it should still be possible to see the differences in the randomly assigned effects. If the study incorporates repeated measurements on human or animal subjects, randomizing the order of treatments they are exposed to can alleviate impacts of them “learning” through the study or changing just due to being studied, something that we would not have to worry about with paper towels.
In observational studies, we do not have the luxury of random assignment, that is, we cannot randomly assign levels of the treatment variables to our subjects, so we cannot guarantee that the only differences between the groups are based on the differences in the explanatory variables. As discussed before, because we can’t control which level of the variables are assigned to the subjects, we cannot make causal inferences and have to worry about other variables being the real drivers of the results. Although we can never establish causal inference with observational studies, we can generalize our results to a larger population if we have a representative (ideally random) sample from our population of interest.
It is also possible that we might have studies where some of the variables are randomly assigned and others that are not randomly assignable. The most common versions of this are what we sometimes call subject “demographics”, such as gender, income, race, etc. We might be performing a study where we can randomly assign treatments to these subjects but might also want to account for differences based on income level, which we can’t assign. In these cases, the scope of inference gets complicated – differences seen on randomized variables can be causally interpreted but you have to be careful to not say that the demographics caused differences. Suppose that a randomly assigned drug dosage is found to show positive differences in older adults and negative changes in younger adults. We could say that the dosage causes the increases in older adults and decreases in younger ones, but we can’t say that age caused the the differences in the ages – it just modified how the drug works and what the drug caused to happen in the responses.
Even when we do have random assignment of treatments it is important to think about who/what is included in the sample. To get back to the paper towel example, we are probably interested in more than the sheets of the rolls we have to work with. If we could randomly select the studied paper towels from all paper towels made by each brand, our conclusions could be extended to those populations. That probably would not be practical, but trying to make sure that the towels are representative of all made by each brand by checking for defects and maybe picking towels from a few different rolls would be a good start to being able to extend inferences beyond the tested towels. But if you were doing this study in the factory, it might be possible to randomly sample from the towels produced, at least over the course of a day.
Once random assignment and random sampling is settled, the final aspect of study design involves deciding on the number of observations that should be made. The short (glib) answer is to take as many as you can afford. With more observations comes higher power to detect differences if they exist, which is a desired attribute of all studies. It is also important to make sure that you obtain multiple observations at each combination of the treatment levels, which are called replicates. Having replicate measurements allows estimation of the mean for each combination of the treatment levels as well as estimation and testing for an interaction. And we always prefer70 having balanced designs because they provide resistance to violation of some assumptions as was discussed in Chapter ??. A balanced design in a Two-Way ANOVA setting involves having the same sample size for every combination of the levels of the treatments.
With two categorical explanatory variables, there are now five possible scenarios for the truth. Different situations are created depending on whether there is an interaction between the two variables, whether both variables are important but do not interact, or whether either of the variables matter at all. Basically, there are five different possible outcomes in a randomized Two-Way ANOVA study, listed in order of increasing model complexity:
Neither A or B has an effect on the responses (nothing causes differences in responses).
A has an effect, B does not (only A causes differences in responses).
B has an effect, A does not (only B causes differences in responses).
Both A and B have effects on response but no interaction (A and B both cause differences in responses but the impacts are additive).
Effect of A on response differs based on the levels of B, the opposite is also true (means for levels of response across A are different for different levels of B, or, simply, A and B interact in their effect on the response).
To illustrate these five potential outcomes, we will consider a fake version of the paper towel example. It ended up being really messy and complicated to actually perform the experiment as described so these data were simulated. The hope is to use this simple example to illustrate some of the Two-Way ANOVA possibilities. The first step is to understand what has been observed (number observations at each combination of factors) and look at some summary statistics across all the “groups”. The data set is available via the following link:
require(readr)
pt <- read_csv("http://www.math.montana.edu/courses/s217/documents/pt.csv")
pt$drops <- factor(pt$drops)
pt$brand <- factor(pt$brand)The data set contains five observations per combination of treatment levels as
provided by the tally function. To get counts for combinations of the
variables, use the general formula of tally(x1~x2, data=...) – noting that the order of x1 and x2 doesn’t matter here:
## drops
## brand 10 20 30
## B1 5 5 5
## B2 5 5 5The sample sizes in each of the six treatment level combinations of Brand
and Drops [(B1, 10), (B1, 20), (B1, 30), (B2, 10), (B2, 20),
(B2, 30)] are \(n_{jk} = 5\) for \(j^{th}\) level of Brand (\(j=1, 2\)) and
\(k^{th}\) level of Drops (\(k=1, 2, 3\)). The tally function gives us an \(R\) by \(C\)
contingency table with \(R = 2\) rows (B1, B2) and \(C = 3\) columns
(10, 20, and 30).
We’ll have more fun with \(R\) by \(C\)
tables in Chapter ?? – here it helps us to see the sample size in
each combination of factor levels. The favstats function also helps us
dig into the results for all combinations of factor levels. The notation
involves putting both factor variables after the “~” with a “+” between them.
In the output, the first row contains summary information for the
5 observations for Brand B1 and Drops amount 10. It also contains the
sample size in the n column, although here it rolled into a new set of
rows with the standard deviations of each combination.
## brand.drops min Q1 median Q3 max mean
## 1 B1.10 0.3892621 1.3158737 1.906436 2.050363 2.333138 1.599015
## 2 B2.10 2.3078095 2.8556961 3.001147 3.043846 3.050417 2.851783
## 3 B1.20 0.3838299 0.7737965 1.516424 1.808725 2.105380 1.317631
## 4 B2.20 1.1415868 1.9382142 2.066681 2.838412 3.001200 2.197219
## 5 B1.30 0.2387500 0.9804284 1.226804 1.555707 1.829617 1.166261
## 6 B2.30 0.5470565 1.1205102 1.284117 1.511692 2.106356 1.313946
## sd n missing
## 1 0.7714970 5 0
## 2 0.3140764 5 0
## 3 0.7191978 5 0
## 4 0.7509989 5 0
## 5 0.6103657 5 0
## 6 0.5686485 5 0The next step is to visually explore the results across the combinations of the two explanatory variables. The pirate-plot can be extended to handle these
sorts of two-way situations using a formula that is something like y~A*B.
The x-axis in the pirate-plot shows two rows of labels based on the two categories and the unique combinations of those categories are directly related to a displayed distribution of responses and mean and confidence interval. For example, in Figure 2.49, the Brand with levels of B1 and B2 is the first row of x-axis labels and they are repeated across the three levels of Drops. In reading these plots, look for differences in the means across the levels of the first row variable (Brand) for each level of the second row variable (Drops) and then focus on whether those differences change across the levels of the second variable – that is an interaction as the differences in differences change.
Specifically, start with comparing the two brands at each amount of water.
Do the brands seem different? Certainly for 10 drops of water the two look
different but not for 30 drops, suggesting a different impact of brands based on the amount of water present. We can also look for combinations of factors
that produce the highest or lowest responses in this display. It appears that
the time to failure is highest in the low water drop groups but as the water
levels increase, the time to failure falls and the differences in the two
brands seem to decrease. The fake data seem to have relatively similar
amounts of variability and distribution shapes except for 10 drops and brand B2 – remembering that there are
only 5 observations available for describing the shape of responses for each
combination. These data were simulated using a normal distribution with
constant variance if that gives you some extra confidence in assessing these
model assumptions.
(ref:fig4-1) Pirate-plot of paper towel data by Drops (x-axis) and Brand
(side of bean, shaded area for Brand B1).
library(yarrr)
set.seed(12)
pirateplot(responses~brand*drops, data=pt, xlab="Drops", ylab="Time", inf.method="ci", point.o=1) 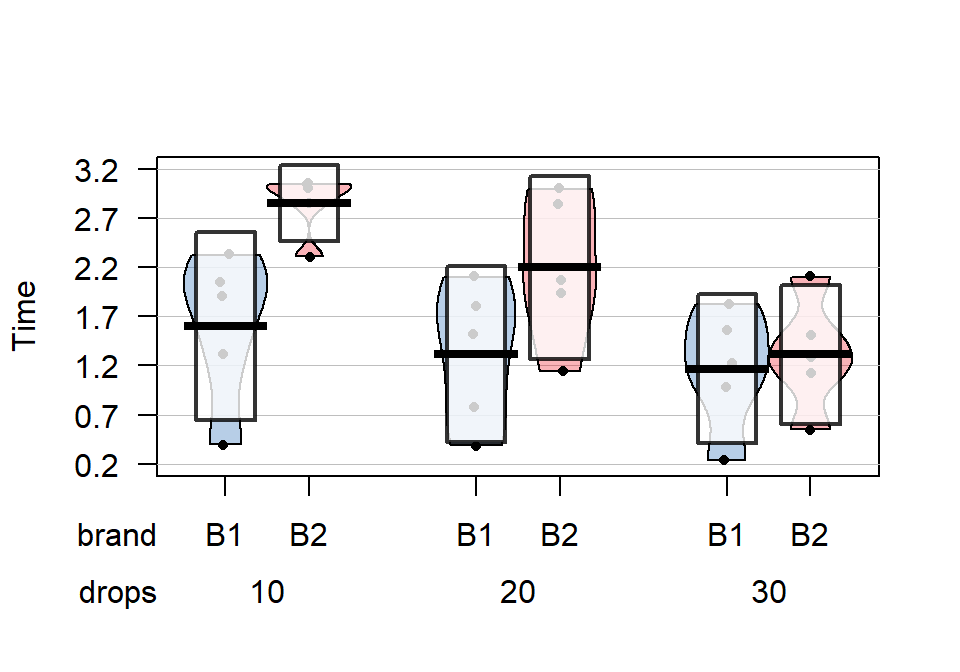
Figure 2.49: (ref:fig4-1)
The pirate-plots can handle situations where both variables have more than two
levels but it can sometimes get a bit cluttered to actually display the data when our analysis is going to focus on means of the responses. The means for each combination
of levels that you can find in the favstats output are more usefully used
in what is called an interaction plot.
Interaction plots display the mean
responses (y-axis) versus levels of one predictor variable on the x-axis,
adding points and separate lines for each level of the other predictor variable. Because
we don’t like any of the available functions in R, we wrote our own function,
called intplot that you can download71 using:
The function allows a formula interface like Y~X1*X2 and provides the
means \(\pm\) 1 SE (vertical bars) and adds a legend to help make
everything clear.
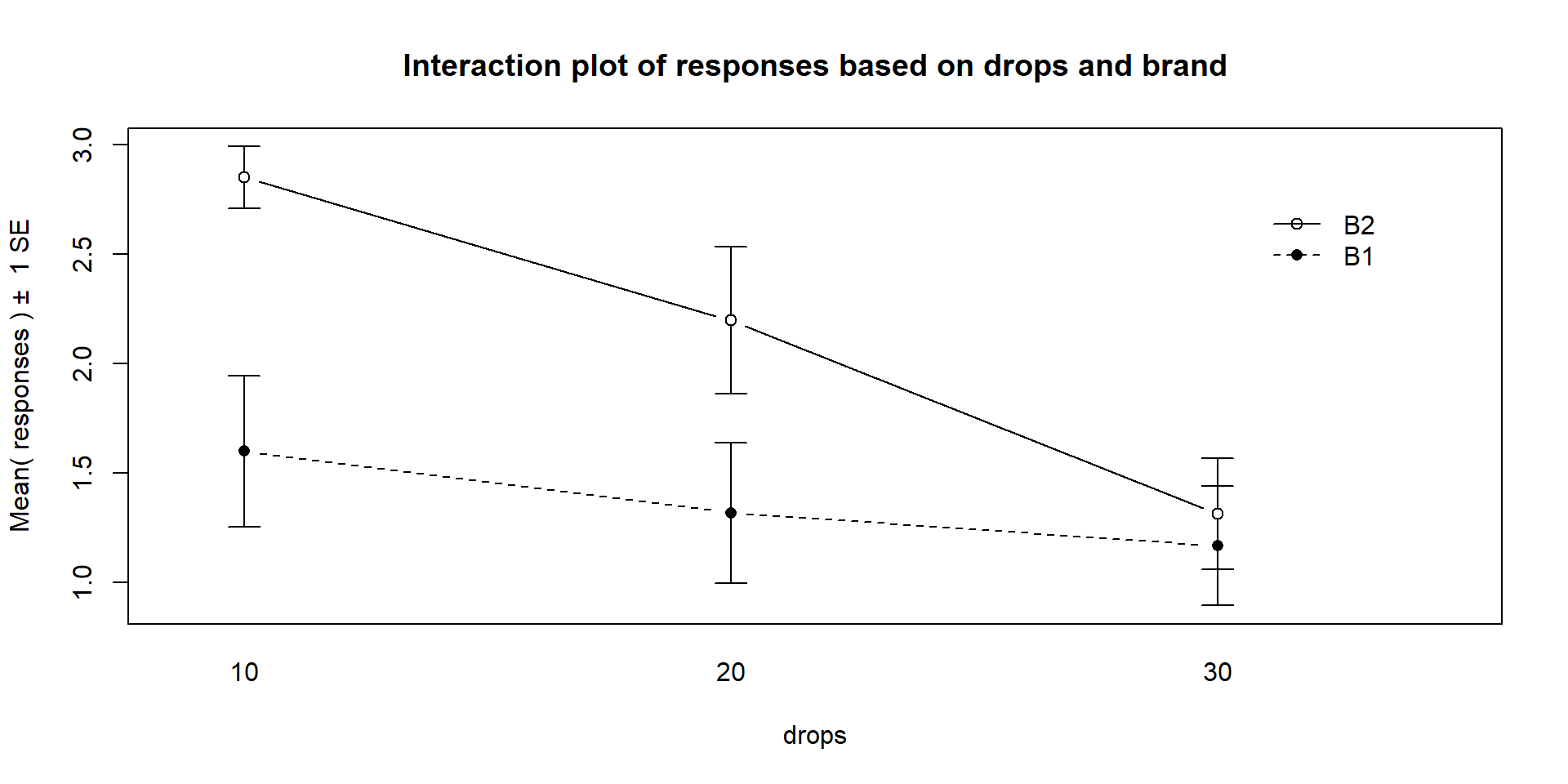
Figure 2.50: Interaction plot of the paper towel data with Drops on the x-axis and different lines based on Brand.
Interaction plots can always be made two different ways by switching the order
of the variables. Figure 2.50 contains Drops on the x-axis
and Figure 2.51 has Brand on the x-axis. Typically putting
the variable with more levels on the x-axis will make interpretation easier,
but not always. Try both and decide on the one that you like best.
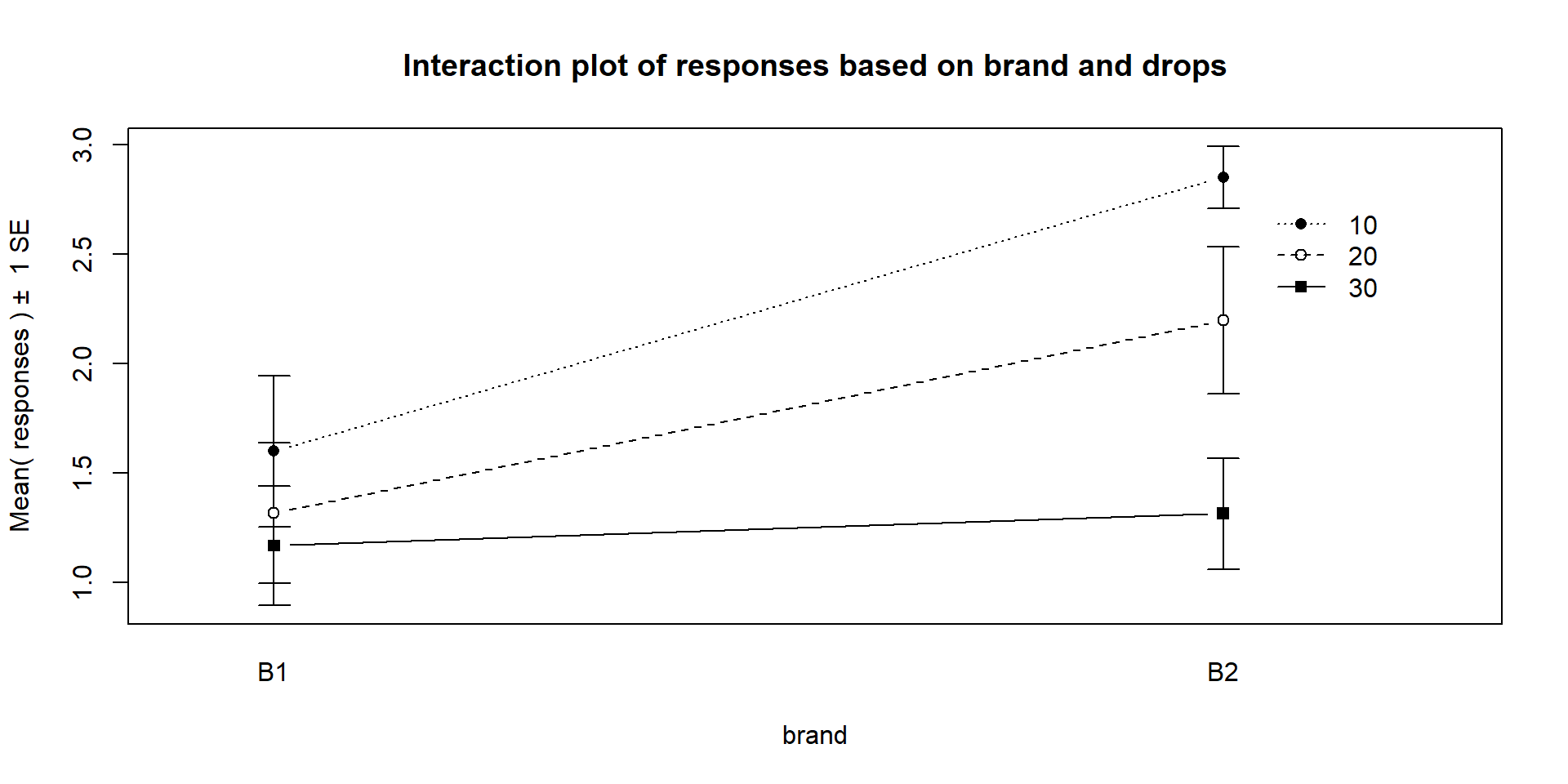
Figure 2.51: Interaction plot of paper towel data with Brand on the x-axis and lines based on Drops.
The formula in this function builds on our previous notation and now we include
both predictor variables with an “*” between them. Using an asterisk between
explanatory variables is one way of telling R to include an interaction between
the variables. While the interaction may or may not be present, the interaction
plot helps us to explore those potential differences.
There are a variety of aspects of the interaction plots to pay attention to. Initially, the question to answer is whether it appears that there is an interaction between the predictor variables. When there is an interaction, you will see non-parallel lines in the interaction plot. You want to look from left to right in the plot and assess whether the lines connecting the means are close to parallel, relative to the amount of variability in the estimated means as represented by the SEs in the bars. If it seems that there is clear visual evidence of non-parallel lines, then the interaction is likely worth considering (we will use a hypothesis test to formally assess this – see the discussion below). If the lines look to be close to parallel, then there probably isn’t an interaction between the variables. Without an interaction present, that means that the differences in the response across levels of one variable doesn’t change based on the levels of the other variable and vice-versa. This means that we can consider the main effects of each variable on their own72. Main effects are much like the results we found in Chapter ?? where we can compare means across levels of a single variable except that there are results for two variables to extract from the model. With the presence of an interaction, it is complicated to summarize how each variable is affecting the response variable because their impacts change depending on the level of the other factor. And plots like the interaction plot provide us with useful information.
If the lines are not parallel, then
focus in on comparing the levels of one variable as the other variable changes.
Remember that the definition of an interaction is that the differences among
levels of one variable depends on the level of the other variable being
considered. “Visually” this means comparing the size of the differences in the
lines from left to right. In Figures 2.50 and 2.51,
the effect of amount of water
changes based on the brand being considered. In Figure 2.51,
the three lines
represent the three water levels. The difference between the brands (left to
right, B1 to B2) is different depending on how much water was present. It
appears that Brand B2 lasted longer at the lower water levels but that the
difference between the two brands dropped as the water levels increased. The
same story appears in Figure 2.50. As the
water levels increase (left to right, 10 to 20 to 30 drops), the differences
between the two brands decrease. Of the two versions, Figure 2.50
is probably easier to read here. Sometimes it is nice to see the interaction plot made both ways simultaneously, so you can also use the intplotarray function, which provides Figure 2.52. This plot also adds pirate-plots to the off-diagonals so you can explore the main effects of each variable, if that is reasonable.
The interaction plots can be used to
identify the best and worst mean responses for combinations of the treatment
levels. For example, 10 Drops and Brand B2 lasts longest, on average, and 30 Drops with Brand B1 fails fastest, on average. In any version of the plot here, the lines do not appear to be parallel suggesting that further exploration of the
interaction appears to be warranted.
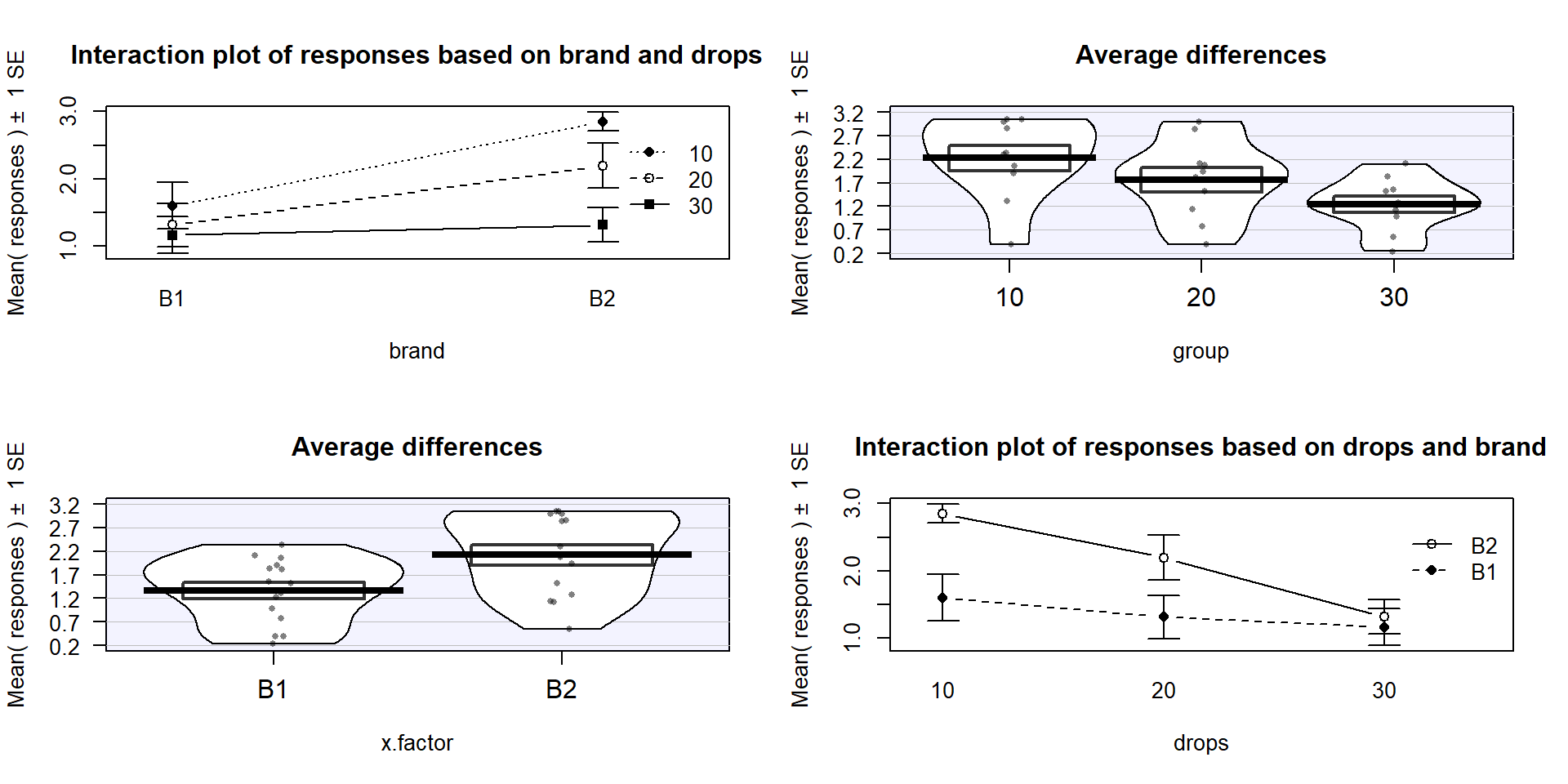
Figure 2.52: Interaction plot array of paper towel data with two different versions of interaction plots and pirate-plots of the responses versus each explanatory variable.
Before we get to the hypothesis tests
to formally make this assessment (you knew some sort of p-value was coming, right?),
we can visualize the 5 different scenarios that could characterize the sorts of
results you could observe in a Two-Way ANOVA situation. Figure 2.53
shows 4 of the 5 scenarios. In panel (a), when there are no differences from either
variable (Scenario 1), it provides relatively parallel lines and basically no
differences either across Drops levels (x-axis) or Brand (lines). Data such as these would
likely result in little to no evidence related to a difference in brands, water
levels, or any interaction between them in this data set.
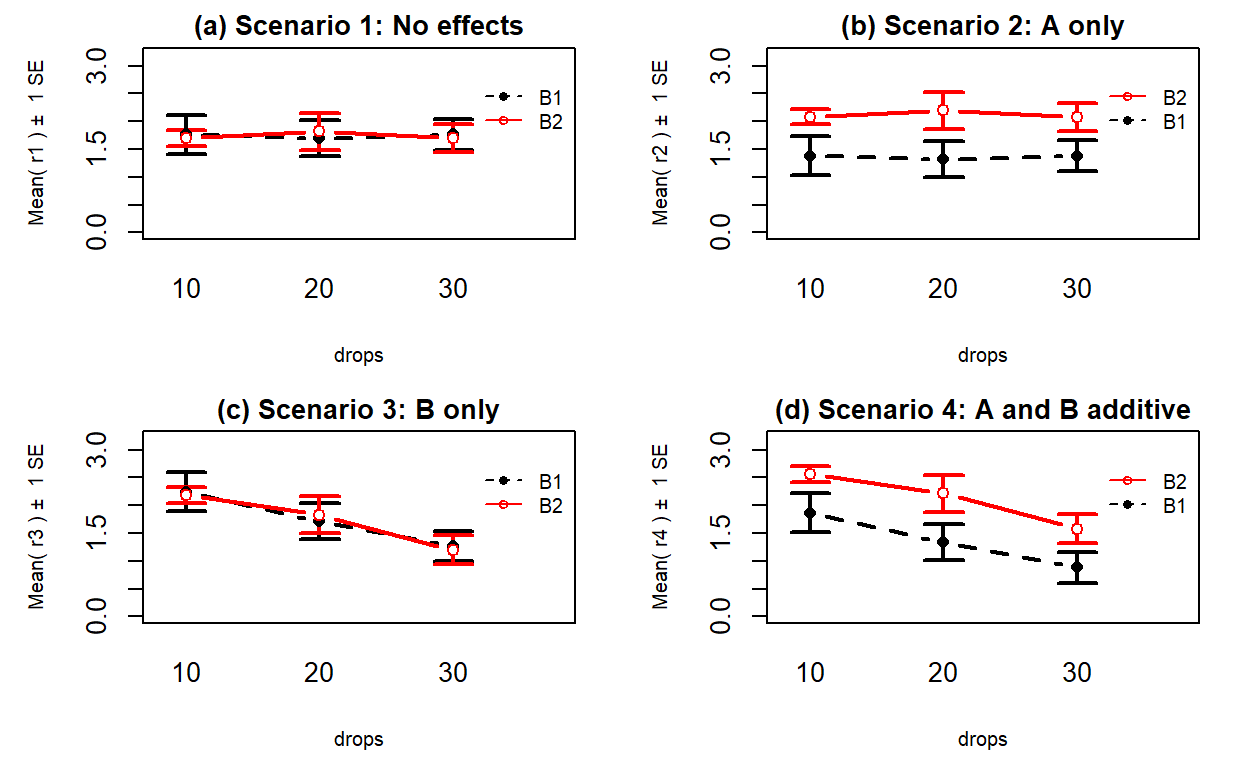
Figure 2.53: Interaction plots of four possible scenarios in the paper towel study.
Scenario 2 (Figure 2.53 panel (b))
incorporates differences based on factor A (here that is Brand) but no real
difference based on the Drops or any interaction. This results in a clear shift between the lines for the means of the Brands but little to no changes in the level of those lines across water levels.
These lines are relatively parallel. We can see that Brand B2 is better than
Brand B1 but that is all we can show with these sorts of results.
Scenario 3 (Figure 2.53 panel (c)) flips the important variable
to B (Drops)
and shows decreasing average times as the water levels increase. Again, the
interaction panels show near parallel-ness in the lines and really just show differences
among the levels of the water. In both Scenarios 2 and 3, we could use a single
variable and drop the other from the model, getting back to a One-Way ANOVA
model, without losing any important information.
Scenario 4 (Figure 2.53 panel (d)) incorporates
effects of A and B, but they are additive. That means that the effect
of one variable is the same across the levels of the other variable. In this
experiment, that would mean that Drops has the same impact on performance
regardless of brand and that the brands differ but each type of difference is
the same regardless of levels of the other variable.
The interaction plot lines are more or less parallel but now the brands are
clearly different from each other. The plot shows the decrease in performance
based on increasing water levels and that Brand B2 is better than
Brand B1. Additive effects show the same difference in lines from left to
right in the interaction plots.
Finally, Scenario 5 (Figure 2.54) involves
an interaction between the two variables (Drops and Brand). There are many ways
that interactions can present but the main thing is to look for clearly
non-parallel lines.
As noted in the previous discussion, the Drops effect
appears to change depending on which level of Brand is being considered.
Note that the plot here described as Scenario 5 is the same as the initial plot
of the results in Figure 2.50.
(ref:fig4-6) Interaction plot of Scenario 5 where it appears that an interaction is present.
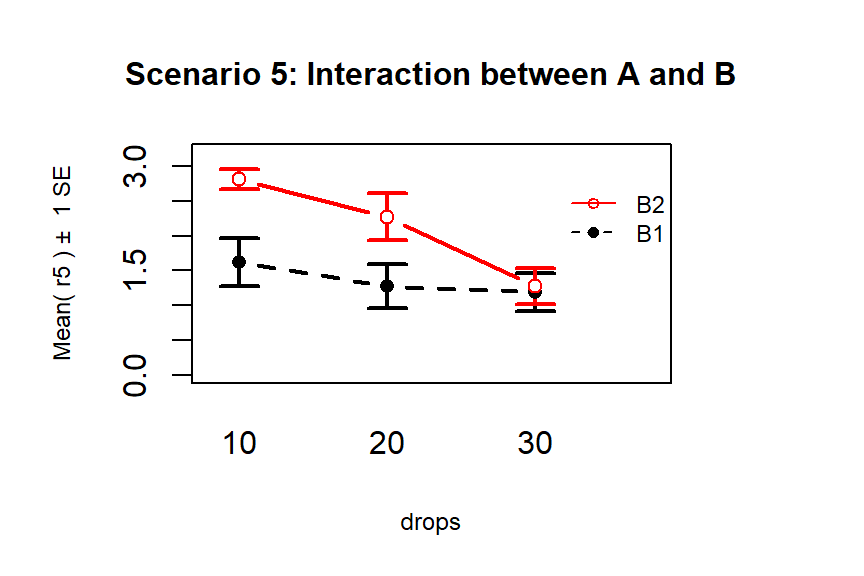
Figure 2.54: (ref:fig4-6)
The typical modeling protocol is to start with assuming that Scenario 5 is a possible description of the results, related to fitting what is called the interaction model, and then attempt to simplify the model (to the additive model) if warranted. We need a hypothesis test to help decide if the interaction is “real”. We start with assuming there is no interaction between the two factors in their impacts on the response and assess evidence against that null hypothesis. We need a hypothesis test because the lines will never be exactly parallel in real data and, just like in the One-Way ANOVA situation, the amount of variation around the lines impacts the ability of the model to detect differences, in this case of an interaction.
We would not suggest throwing away observations to get balanced designs. Plan in advance to try to have a balanced design but analyze the responses you get.↩
Copy and include this code in a codechunk any time you want to use the
intplotorinplotarrayfunctions↩We will use “main effects” to refer to the two explanatory variables in the additive model even if they are not randomly assigned to contrast with having those variables interacting in the model. It is the one place in the book where we use “effects” without worrying about the causal connotation of that word.↩