- Cover
- Acknowledgments
- 1 Preface
- 2 (R)e-Introduction to statistics
- 2.1 Histograms, boxplots, and density curves
- 2.2 Pirate-plots
- 2.3 Models, hypotheses, and permutations for the two sample mean situation
- 2.4 Permutation testing for the two sample mean situation
- 2.5 Hypothesis testing (general)
- 2.6 Connecting randomization (nonparametric) and parametric tests
- 2.7 Second example of permutation tests
- 2.8 Reproducibility Crisis: Moving beyond p < 0.05, publication bias, and multiple testing issues
- 2.9 Confidence intervals and bootstrapping
- 2.10 Bootstrap confidence intervals for difference in GPAs
- 2.11 Chapter summary
- 2.12 Summary of important R code
- 2.13 Practice problems
- 3 One-Way ANOVA
- 3.1 Situation
- 3.2 Linear model for One-Way ANOVA (cell-means and reference-coding)
- 3.3 One-Way ANOVA Sums of Squares, Mean Squares, and F-test
- 3.4 ANOVA model diagnostics including QQ-plots
- 3.5 Guinea pig tooth growth One-Way ANOVA example
- 3.6 Multiple (pair-wise) comparisons using Tukey’s HSD and the compact letter display
- 3.7 Pair-wise comparisons for the Overtake data
- 3.8 Chapter summary
- 3.9 Summary of important R code
- 3.10 Practice problems
- 4 Two-Way ANOVA
- 4.1 Situation
- 4.2 Designing a two-way experiment and visualizing results
- 4.3 Two-Way ANOVA models and hypothesis tests
- 4.4 Guinea pig tooth growth analysis with Two-Way ANOVA
- 4.5 Observational study example: The Psychology of Debt
- 4.6 Pushing Two-Way ANOVA to the limit: Un-replicated designs and Estimability
- 4.7 Chapter summary
- 4.8 Summary of important R code
- 4.9 Practice problems
- 5 Chi-square tests
- 5.1 Situation, contingency tables, and tableplots
- 5.2 Homogeneity test hypotheses
- 5.3 Independence test hypotheses
- 5.4 Models for R by C tables
- 5.5 Permutation tests for the \(X^2\) statistic
- 5.6 Chi-square distribution for the \(X^2\) statistic
- 5.7 Examining residuals for the source of differences
- 5.8 General protocol for \(X^2\) tests
- 5.9 Political party and voting results: Complete analysis
- 5.10 Is cheating and lying related in students?
- 5.11 Analyzing a stratified random sample of California schools
- 5.12 Chapter summary
- 5.13 Summary of important R commands
- 5.14 Practice problems
- 6 Correlation and Simple Linear Regression
- 6.1 Relationships between two quantitative variables
- 6.2 Estimating the correlation coefficient
- 6.3 Relationships between variables by groups
- 6.4 Inference for the correlation coefficient
- 6.5 Are tree diameters related to tree heights?
- 6.6 Describing relationships with a regression model
- 6.7 Least Squares Estimation
- 6.8 Measuring the strength of regressions: R2
- 6.9 Outliers: leverage and influence
- 6.10 Residual diagnostics – setting the stage for inference
- 6.11 Old Faithful discharge and waiting times
- 6.12 Chapter summary
- 6.13 Summary of important R code
- 6.14 Practice problems
- 7 Simple linear regression inference
- 7.1 Model
- 7.2 Confidence interval and hypothesis tests for the slope and intercept
- 7.3 Bozeman temperature trend
- 7.4 Randomization-based inferences for the slope coefficient
- 7.5 Transformations part I: Linearizing relationships
- 7.6 Transformations part II: Impacts on SLR interpretations: log(y), log(x), & both log(y) & log(x)
- 7.7 Confidence interval for the mean and prediction intervals for a new observation
- 7.8 Chapter summary
- 7.9 Summary of important R code
- 7.10 Practice problems
- 8 Multiple linear regression
- 8.1 Going from SLR to MLR
- 8.2 Validity conditions in MLR
- 8.3 Interpretation of MLR terms
- 8.4 Comparing multiple regression models
- 8.5 General recommendations for MLR interpretations and VIFs
- 8.6 MLR inference: Parameter inferences using the t-distribution
- 8.7 Overall F-test in multiple linear regression
- 8.8 Case study: First year college GPA and SATs
- 8.9 Different intercepts for different groups: MLR with indicator variables
- 8.10 Additive MLR with more than two groups: Headache example
- 8.11 Different slopes and different intercepts
- 8.12 F-tests for MLR models with quantitative and categorical variables and interactions
- 8.13 AICs for model selection
- 8.14 Case study: Forced expiratory volume model selection using AICs
- 8.15 Chapter summary
- 8.16 Summary of important R code
- 8.17 Practice problems
- 9 Case studies
- 9.1 Overview of material covered
- 9.2 The impact of simulated chronic nitrogen deposition on the biomass and N2-fixation activity of two boreal feather moss–cyanobacteria associations
- 9.3 Ants learn to rely on more informative attributes during decision-making
- 9.4 Multi-variate models are essential for understanding vertebrate diversification in deep time
- 9.5 What do didgeridoos really do about sleepiness?
- 9.6 General summary
- References
2.9 Confidence intervals and bootstrapping
Up to this point the focus has been on hypotheses, p-values, and estimates of the size of differences. But so far this has not explored inference techniques for the size of the difference. Confidence intervals provide an interval where we are __% confident that the true parameter lies. The idea of “confidence” is that if we repeated randomly sampling from the same population and made a similar confidence interval, the collection of all these confidence intervals would contain the true parameter at the specified confidence level (usually 95%). We only get to make one interval and so it either has the true parameter in it or not, and we don’t know the truth in real situations.
Confidence intervals can be constructed with parametric and a nonparametric approaches. The nonparametric approach will be using what is called bootstrapping and draws its name from “pull yourself up by your bootstraps” where you improve your situation based on your own efforts. In statistics, we make our situation or inferences better by re-using the observations we have by assuming that the sample represents the population. Since each observation represents other similar observations in the population that we didn’t get to measure, if we sample with replacement to generate a new data set of size n from our data set (also of size n) it mimics the process of taking repeated random samples of size \(n\) from our population of interest. This process also ends up giving us useful sampling distributions of statistics even when our standard normality assumption is violated, similar to what we encountered in the permutation tests. Bootstrapping is especially useful in situations where we are interested in statistics other than the mean (say we want a confidence interval for a median or a standard deviation) or when we consider functions of more than one parameter and don’t want to derive the distribution of the statistic (say the difference in two medians). Here, bootstrapping is used to provide more trustworthy inferences when some of our assumptions (especially normality) might be violated for our parametric confidence interval procedure.
To perform bootstrapping, the resample function from the
mosaic package will be used. We can apply this function to a data set and get a new
version of the
data set by sampling new observations with replacement from the original one43.
The new, bootstrapped version of the data set (called dsample_BTS below)
contains a new variable called orig.id which is the number of the subject
from the original data set. By summarizing how often each of these id’s
occurred in a bootstrapped data set, we can see how the re-sampling works.
The table function will count up how many times each observation was used in
the bootstrap sample,
providing a row with the id followed by a row with the
count44. In the first bootstrap
sample shown, the 1st, 14th, and 26th observations
were sampled twice, the 9th and 28th observations were sampled four
times, and the 4th, 5th, 6th, and many others
were not sampled at all. Bootstrap sampling thus picks some observations
multiple times and to do that it has to ignore some45 observations.
##
## 1 2 3 7 8 9 10 11 12 13 14 16 18 19 23 24 25 26 27 28 30
## 2 1 1 1 1 4 1 1 1 1 2 1 1 1 1 1 1 2 1 4 1Like in permutations, one randomization isn’t enough. A second bootstrap sample is also provided to help you get a sense of what bootstrap data sets contain. It did not select observations two through five but did select eight others more than once. You can see other variations in the resulting re-sampling of subjects with the most sampled observation used four times. With \(n=30\), the the chance of selecting any observation for any slot in the new data set is \(1/30\) and the expected or mean number of appearances we expect to see for an observation is the number of random draws times the probably of selection on each so \(30*1/30=1\). So we expect to see each observation in the bootstrap sample on average once but random variability in the samples then creates the possibility of seeing it more than once or not all.
##
## 1 6 7 8 9 10 11 12 13 16 17 20 22 23 24 25 26 28 30
## 2 2 1 1 2 1 4 1 3 1 1 1 2 2 1 1 2 1 1We can use the two results to get an idea of distribution of results in terms of number of times observations might be re-sampled when sampling with replacement and the variation in those results, as shown in Figure 2.23. We could also derive the expected counts for each number of times of re-sampling when we start with all observations having an equal chance and sampling with replacement but this isn’t important for using bootstrapping methods.
Figure 2.23: Counts of number of times of observation (or not observed for times re-sampled of 0) for two bootstrap samples.
The main point of this exploration was to see that each run of the
resample function provides a new version of the data set. Repeating this
\(B\) times using
another for loop, we will track our quantity of interest, say \(T\), in all
these new “data sets” and call those results \(T^*\). The distribution of the
bootstrapped
\(T^*\) statistics tells us about the range of results to expect
for the statistic. The middle % of the \(T^*\)’s provides a %
bootstrap confidence interval46 for the true parameter – here the difference in the two population means.
To make this concrete, we can revisit our previous examples, starting
with the dsample data created before and our interest in comparing the
mean passing distances for the commuter and casual outfit groups in the \(n=30\) stratified random sample that was extracted. The
bootstrapping code is very similar to the permutation code except that we apply
the resample function to the entire data set used in lm as opposed to the shuffle
function that was applied only to the explanatory variable.
## Conditioncommute
## -25.93333B <- 1000
set.seed(1234)
Tstar <- matrix(NA, nrow=B)
for (b in (1:B)){
lmP <- lm(Distance~Condition, data=resample(dsample))
Tstar[b] <- coef(lmP)[2]
}
favstats(Tstar)## min Q1 median Q3 max mean sd n
## -66.96429 -34.57159 -25.65881 -17.12391 17.17857 -25.73641 12.30987 1000
## missing
## 0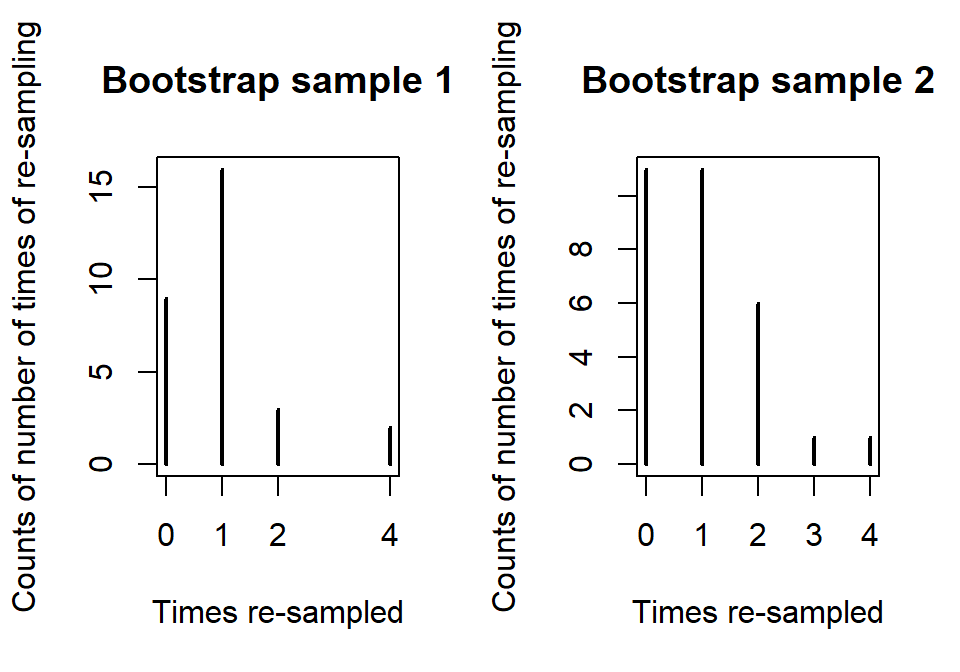
Figure 2.24: Histogram and density curve of bootstrap distributions of difference in sample mean Distances with vertical line for the observed difference in the means of -25.933.
hist(Tstar, labels=T)
abline(v=Tobs, col="red", lwd=2)
plot(density(Tstar), main="Density curve of Tstar")
abline(v=Tobs, col="red", lwd=2)In this situation, the observed difference in the mean passing distances is -25.933 cm (commute - casual), which is the bold vertical line in Figure 2.24. The bootstrap distribution shows the results for the difference in the sample means when fake data sets are re-constructed by sampling from the original data set with replacement. The bootstrap distribution is approximately centered at the observed value (difference in the sample means) and is relatively symmetric.
The permutation distribution in the same situation (Figure 2.11) had a similar shape but was centered at 0. Permutations create sampling distributions based on assuming the null hypothesis is true, which is useful for hypothesis testing. Bootstrapping creates distributions centered at the observed result, which is the sampling distribution “under the alternative” or when no null hypothesis is assumed; bootstrap distributions are useful for generating confidence intervals for the true parameter values.
To create a 95% bootstrap confidence interval for the difference in
the true mean distances (\(\mu_\text{commute}-\mu_\text{casual}\)), select the
middle 95% of results from
the bootstrap distribution. Specifically, find the 2.5th
percentile and the 97.5th percentile (values that put 2.5 and 97.5%
of the results to the left) in the bootstrap distribution, which leaves 95% in
the middle for the confidence interval. To find percentiles in a distribution
in R, functions are of the form q[Name of distribution], with the function
qt extracting percentiles from a \(t\)-distribution (examples below). From the
bootstrap results, use the qdata function on the Tstar results that
contain the bootstrap distribution of the statistic of interest.
## p quantile
## 0.0250 -50.0055## p quantile
## 0.975000 -2.248774These results tell us that the 2.5th percentile of the bootstrap distribution is at -50.01 cm and the 97.5th percentile is at -2.249 cm. We can combine these results to provide a 95% confidence for \(\mu_\text{commute}-\mu_\text{casaual}\) that is between -50 and -2.25 cm. This interval is interpreted as with any confidence interval, that we are 95% confident that the difference in the true mean distances (commute minus casual groups) is between -50 and -2.25 cm. Or we can switch the direction of the comparison and say that we are 95% confident that the difference in the true means is between 2.25 and 50 cm (casual minus commute). This result would be incorporated into step 5 of the hypothesis testing protocol to accompany discussing the size of the estimated difference in the groups or used as a result of interest in itself. Both percentiles can be obtained in one line of code using:
## quantile p
## 2.5% -50.005502 0.025
## 97.5% -2.248774 0.975Figure 2.25 displays those same percentiles on the bootstrap distribution residing in Tstar.
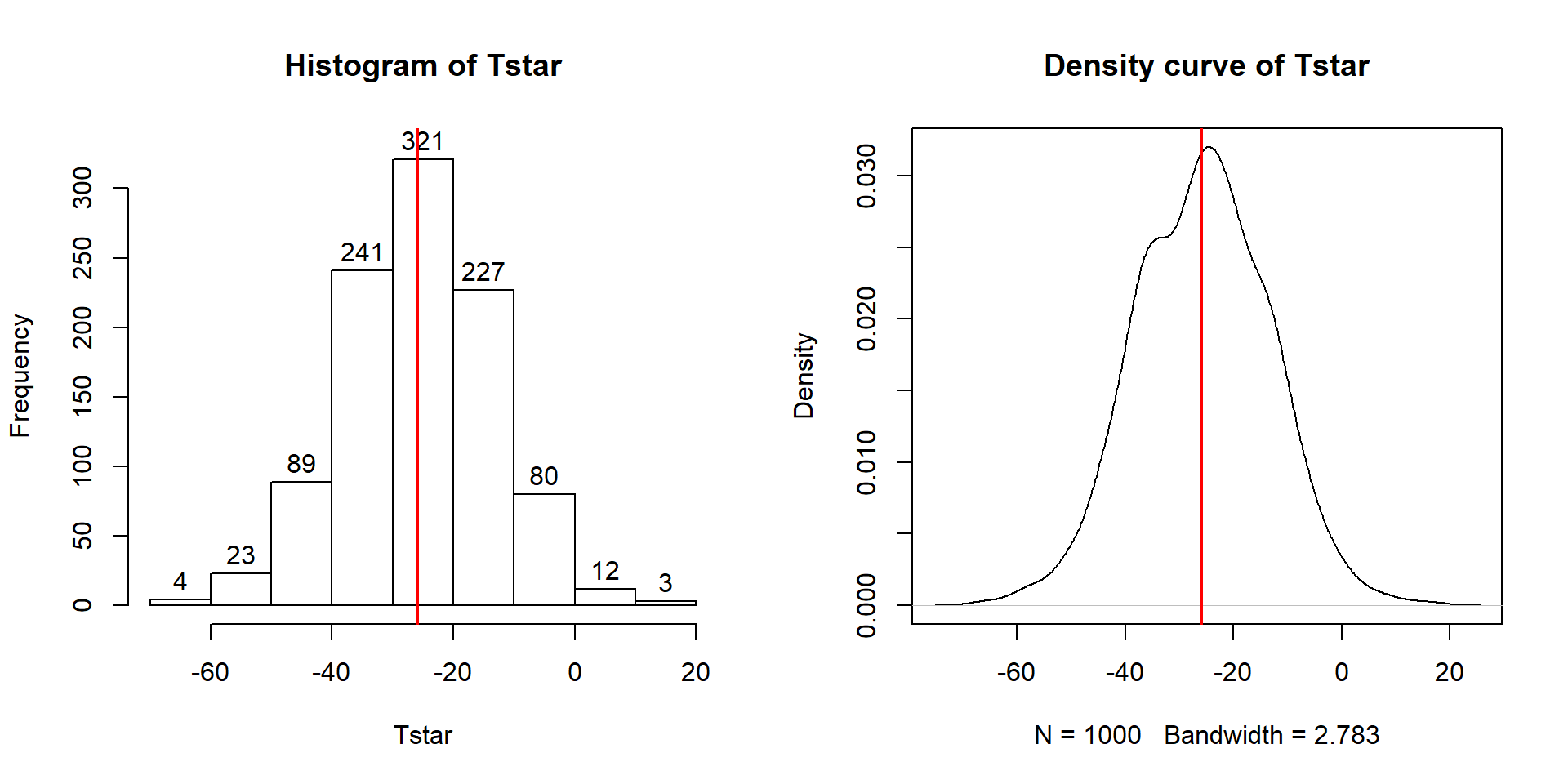
Figure 2.25: Histogram and density curve of bootstrap distribution with 95% bootstrap confidence intervals displayed (bold vertical lines).
hist(Tstar, labels=T)
abline(v=quantiles$quantile, col="blue", lwd=3)
plot(density(Tstar), main="Density curve of Tstar")
abline(v=quantiles$quantile, col="blue", lwd=3)Although confidence intervals can exist without referencing hypotheses, we can revisit our previous hypotheses and see what this confidence interval tells us about the test of \(H_0: \mu_\text{commute} = \mu_\text{casual}\). This null hypothesis is equivalent to testing \(H_0: \mu_\text{commute} - \mu_\text{casual} = 0\), that the difference in the true means is equal to 0 cm. And the difference in the means was the scale for our confidence interval, which did not contain 0 cm. The 0 cm values is an interesting reference value for the confidence interval, because here it is the value where the true means are equal to each other (have a difference of 0 cm). In general, if our confidence interval does not contain 0, then it is saying that 0 is not one of the likely values for the difference in the true means at the selected confidence level. This implies that we should reject a claim that they are equal. This provides the same inferences for the hypotheses that we considered previously using both parametric and permutation approaches using a fixed \(\alpha\) approach where \(\alpha\) = 1 - confidence level.
The general summary is that we can use confidence intervals to test hypotheses by assessing whether the reference value under the null hypothesis is in the confidence interval (suggests insufficient evidence against \(H_0\) to reject it, at least at the \(\alpha\) level and equivalent to having a p-value larger than \(\alpha\)) or outside the confidence interval (sufficient evidence against \(H_0\) to reject it and equivalent to having a p-value that is less than \(\alpha\)). P-values are more informative about hypotheses (measure of evidence against the null hypothesis) but confidence intervals are more informative about the size of differences, so both offer useful information and, as shown here, can provide consistent conclusions about hypotheses. But it is best practice to use p-values to assess evidence against null hypotheses and confidence intervals to do inferences for the size of differences.
As in the previous situation, we also want to consider the parametric
approach
for comparison purposes and to have that method available, especially to help
us understand some methods where we will only consider parametric inferences
in later chapters. The parametric confidence interval is called the
equal variance, two-sample t confidence interval and additionally
assumes that the populations
being sampled from are normally distributed instead of just that they have similar shapes in the bootstrap approach. The parametric method leads to using a \(t\)-distribution
to form the interval with the degrees of freedom for the \(t\)-distribution of \(n-2\) although we can obtain it without direct reference to this distribution using the confint` function applied to thelm`` model. This function generates two confidence intervals and the one in the second row is the one we are interested as it pertains to the difference in the true means of the two groups. The parametric 95% confidence interval here is from -51.6 to -0.26 cm which is a bit different in width from the nonparametric bootstrap interval that was from -50 and -2.25 cm.
## 2.5 % 97.5 %
## (Intercept) 117.64498 153.9550243
## Conditioncommute -51.60841 -0.2582517The bootstrap interval was narrower by almost 4 cm and its upper limit was much further from 0. The bootstrap CI can vary depending on the random number seed used and additional runs of the code produced intervals of (-49.6, -2.8), (-48.3, -2.5), and (-50.9, -1.1) so the differences between the parametric and nonparametric approaches was not just due to an unusual bootstrap distribution. It is not entirely clear why the two intervals differ but there are slightly more results in the left tail of Figure 2.25 than in the right tail and this shifts the 95% confidence slightly away from 0 as compared to the parametric approach. All intervals have the same interpretation, only the methods for calculating the intervals and the assumptions differ. Specifically, the bootstrap interval can tolerate different distribution shapes other than normal and still provide intervals that work well47. The other assumptions are all the same as for the hypothesis test, where we continue to assume that we have independent observations with equal variances for the two groups and maintain concerns about inferences here due to the violation of independence in these responses.
The formula that lm is using to calculate the parametric
equal variance, two-sample \(t\)-based confidence interval is:
\[\bar{x}_1 - \bar{x}_2 \mp t^*_{df}s_p\sqrt{\frac{1}{n_1}+\frac{1}{n_2}}\]
In this situation, the df is again \(n_1+n_2-2\) (the total sample size - 2) and \(s_p = \sqrt{\frac{(n_1-1)s_1^2 + (n_2-1)s_2^2}{n_1+n_2-2}}\). The \(t^*_{df}\) is a multiplier that comes from finding the percentile from the \(t\)-distribution that puts \(C\)% in the middle of the distribution with \(C\) being the confidence level. It is important to note that this \(t^*\) has nothing to do with the previous test statistic \(t\). It is confusing and students first engaging these two options often happily take the result from a test statistic calculation and use it for a multiplier in a \(t\)-based confidence interval – try to focus on which \(t\) you are interested in before you use either. Figure 2.26 shows the \(t\)-distribution with 28 degrees of freedom and the cut-offs that put 95% of the area in the middle.
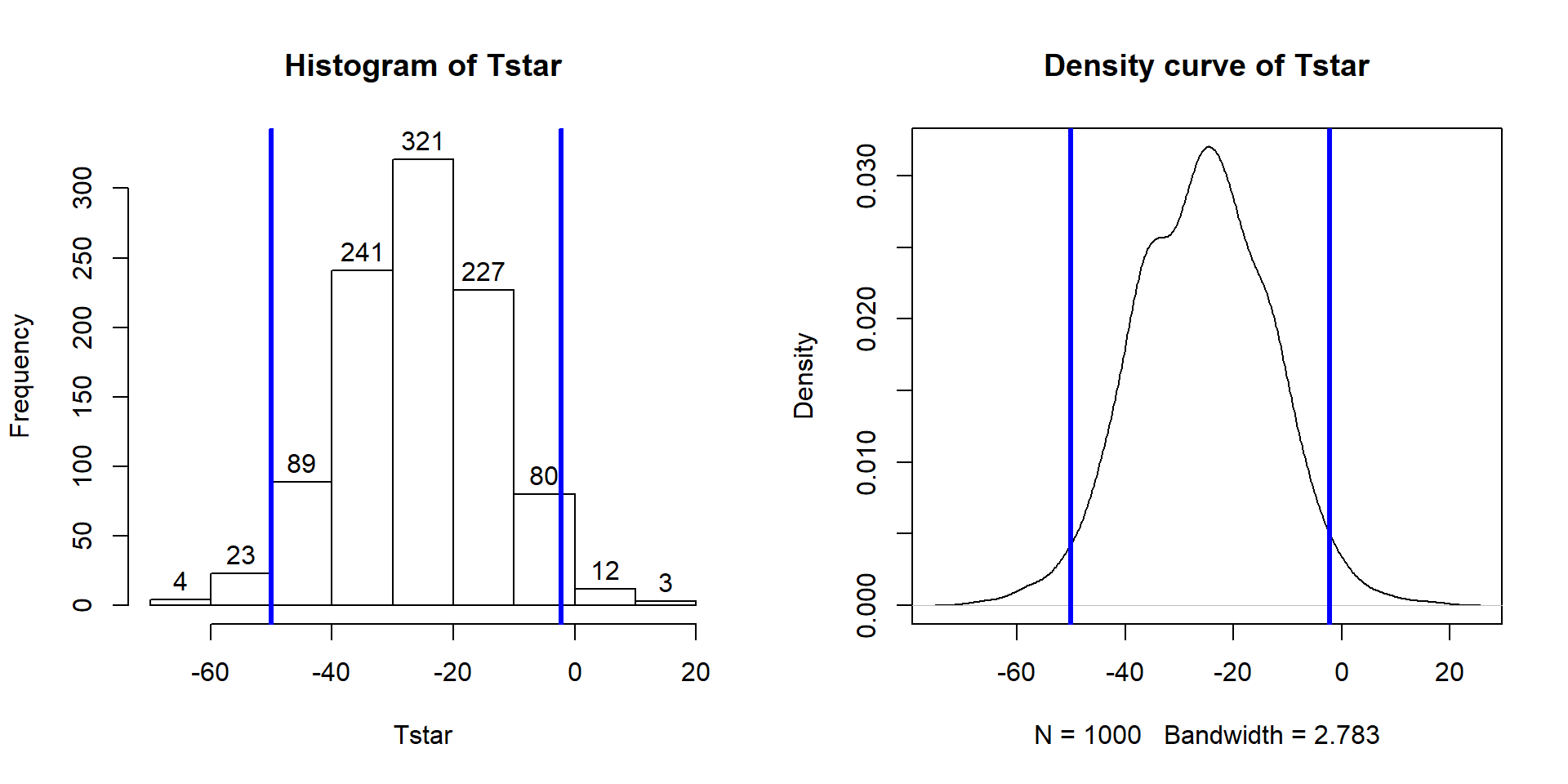
Figure 2.26: Plot of \(t(28)\) with cut-offs for putting 95% of distribution in the middle that delineate the \(t^*\) multiplier to make a 95% confidence interval.
For 95% confidence intervals, the multiplier is going to be close to 2 and
anything else is a likely indication of a mistake. We can use R to get the multipliers for
confidence intervals using the qt function in a similar fashion to how
qdata was used in the bootstrap results, except that this new value must be
used in the previous confidence interval formula. This function produces values
for requested percentiles, so if we want to put 95% in the middle, we place
2.5% in each tail of the distribution and need to request the 97.5th
percentile. Because the \(t\)-distribution is always symmetric around 0, we merely
need to look up the value for the 97.5th percentile and know that the
multiplier for the 2.5th percentile is just \(-t^*\). The \(t^*\)
multiplier to form the confidence interval is 2.0484 for a 95% confidence interval
when the \(df=28\) based on the results from qt:
## [1] 2.048407Note that the 2.5th percentile is just the negative of this value due to symmetry and the real source of the minus in the minus/plus in the formula for the confidence interval.
## [1] -2.048407We can also re-write the confidence interval formula into a slightly more general forms as
\[\bar{x}_1 - \bar{x}_2 \mp t^*_{df}SE_{\bar{x}_1 - \bar{x}_2}\ \text{ OR }\ \bar{x}_1 - \bar{x}_2 \mp ME\]
where \(SE_{\bar{x}_1 - \bar{x}_2} = s_p\sqrt{\frac{1}{n_1}+\frac{1}{n_2}}\) and
\(ME = t^*_{df}SE_{\bar{x}_1 - \bar{x}_2}\). The SE is available in the lm model summary for the line related to the difference in groups in the “Std. Error” column. In some situations, researchers will
report the standard error (SE) or margin of error (ME) as a method
of quantifying the uncertainty in a statistic. The SE is an estimate of the
standard deviation of the statistic (here \(\bar{x}_1 - \bar{x}_2\)) and the ME
is an estimate of the precision of a statistic that can be used to directly
form a confidence interval. The ME depends on the choice of confidence level
although 95% is almost always selected.
To finish this example, R can be used to help you do calculations much
like a calculator except with much more power “under the hood”. You have to
make sure you are careful with using ( ) to group items and remember that
the asterisk (*) is used for multiplication. We need the pertinent
information which is available from the favstats output repeated below to
calculate the confidence interval “by hand”48 using R.
## Condition min Q1 median Q3 max mean sd n missing
## 1 casual 72 112.5 143 154.5 208 135.8000 39.36133 15 0
## 2 commute 60 88.5 113 123.0 168 109.8667 28.41244 15 0Start with typing the following command to calculate \(s_p\) and store it in a
variable named sp:
## [1] 34.32622Then calculate the confidence interval that confint provided using:
## [1] -51.6083698 -0.2582302Or using the information from the model summary:
## [1] -51.6077351 -0.2582649The previous results all use c(-1, 1) times the margin of error to subtract and add
the ME to the difference in the sample means (\(109.8667-135.8\)), which generates the
lower and then upper bounds of the confidence interval. If desired, we can also
use just the last portion of the calculation to find the margin of error,
which is 25.675 here.
## [1] 25.67507For the entire \(n=1,636\) data set for these two groups, the results are obtained using the following code. The estimated difference in the means is -3 cm (commute minus casual). The \(t\)-based 95% confidence interval is from -5.89 to -0.11.
## 2.5 % 97.5 %
## (Intercept) 117.64498 153.9550243
## Conditioncommute -51.60841 -0.2582517The bootstrap 95% confidence interval is from -5.82 to -0.076. With this large data set, the differences between parametric and permutation approaches decrease and they essentially equivalent here. The bootstrap distribution (not displayed) for the differences in the sample means is relatively symmetric and centered around the estimated difference of -3 cm. So using all the observations we would be 95% confident that the true mean difference in overtake distances (commute - casual) is between -5.89 and -0.11 cm, providing additional information about the estimated difference in the sample means of -3 cm.
## Conditioncommute
## -3.003105B <- 1000
set.seed(1234)
Tstar <- matrix(NA, nrow=B)
for (b in (1:B)){
lmP <- lm(Distance~Condition, data=resample(ddsub))
Tstar[b] <- coef(lmP)[2]
}
qdata(Tstar, c(0.025, 0.975))## quantile p
## 2.5% -5.81626474 0.025
## 97.5% -0.07606663 0.975Some perform bootstrap sampling in this situation by re-sampling within each of the groups. We will discuss using this technique in situations without clearly defined groups, so prefer to sample with replacement from the entire data set. It also directly corresponds to situations where the data came from one large sample and then the grouping variable of interest was measured on the \(n\) subjects.↩
The
as.numericfunction is also used here. It really isn’t important but makes sure the output oftableis sorted by observation number by first converting the orig.id variable into a numeric vector.↩In any bootstrap sample, about 1/3 of the observations are not used at all.↩
There are actually many ways to use this information to make a confidence interval. We are using the simplest method that is called the “percentile” method.↩
When hypothesis tests “work well” they have high power to detect differences while having Type I error rates that are close to what we choose a priori. When confidence intervals “work well”, they contain the true parameter value in repeated random samples at around the selected confidence level, which is called the coverage rate. ↩
We will often use this term to indicate perform a calculation using the
favstatsresults – not that you need to go back to the data set and calculate the means and standard deviations yourself.↩