- Cover
- Acknowledgments
- 1 Preface
- 2 (R)e-Introduction to statistics
- 2.1 Histograms, boxplots, and density curves
- 2.2 Pirate-plots
- 2.3 Models, hypotheses, and permutations for the two sample mean situation
- 2.4 Permutation testing for the two sample mean situation
- 2.5 Hypothesis testing (general)
- 2.6 Connecting randomization (nonparametric) and parametric tests
- 2.7 Second example of permutation tests
- 2.8 Reproducibility Crisis: Moving beyond p < 0.05, publication bias, and multiple testing issues
- 2.9 Confidence intervals and bootstrapping
- 2.10 Bootstrap confidence intervals for difference in GPAs
- 2.11 Chapter summary
- 2.12 Summary of important R code
- 2.13 Practice problems
- 3 One-Way ANOVA
- 3.1 Situation
- 3.2 Linear model for One-Way ANOVA (cell-means and reference-coding)
- 3.3 One-Way ANOVA Sums of Squares, Mean Squares, and F-test
- 3.4 ANOVA model diagnostics including QQ-plots
- 3.5 Guinea pig tooth growth One-Way ANOVA example
- 3.6 Multiple (pair-wise) comparisons using Tukey’s HSD and the compact letter display
- 3.7 Pair-wise comparisons for the Overtake data
- 3.8 Chapter summary
- 3.9 Summary of important R code
- 3.10 Practice problems
- 4 Two-Way ANOVA
- 4.1 Situation
- 4.2 Designing a two-way experiment and visualizing results
- 4.3 Two-Way ANOVA models and hypothesis tests
- 4.4 Guinea pig tooth growth analysis with Two-Way ANOVA
- 4.5 Observational study example: The Psychology of Debt
- 4.6 Pushing Two-Way ANOVA to the limit: Un-replicated designs and Estimability
- 4.7 Chapter summary
- 4.8 Summary of important R code
- 4.9 Practice problems
- 5 Chi-square tests
- 5.1 Situation, contingency tables, and tableplots
- 5.2 Homogeneity test hypotheses
- 5.3 Independence test hypotheses
- 5.4 Models for R by C tables
- 5.5 Permutation tests for the \(X^2\) statistic
- 5.6 Chi-square distribution for the \(X^2\) statistic
- 5.7 Examining residuals for the source of differences
- 5.8 General protocol for \(X^2\) tests
- 5.9 Political party and voting results: Complete analysis
- 5.10 Is cheating and lying related in students?
- 5.11 Analyzing a stratified random sample of California schools
- 5.12 Chapter summary
- 5.13 Summary of important R commands
- 5.14 Practice problems
- 6 Correlation and Simple Linear Regression
- 6.1 Relationships between two quantitative variables
- 6.2 Estimating the correlation coefficient
- 6.3 Relationships between variables by groups
- 6.4 Inference for the correlation coefficient
- 6.5 Are tree diameters related to tree heights?
- 6.6 Describing relationships with a regression model
- 6.7 Least Squares Estimation
- 6.8 Measuring the strength of regressions: R2
- 6.9 Outliers: leverage and influence
- 6.10 Residual diagnostics – setting the stage for inference
- 6.11 Old Faithful discharge and waiting times
- 6.12 Chapter summary
- 6.13 Summary of important R code
- 6.14 Practice problems
- 7 Simple linear regression inference
- 7.1 Model
- 7.2 Confidence interval and hypothesis tests for the slope and intercept
- 7.3 Bozeman temperature trend
- 7.4 Randomization-based inferences for the slope coefficient
- 7.5 Transformations part I: Linearizing relationships
- 7.6 Transformations part II: Impacts on SLR interpretations: log(y), log(x), & both log(y) & log(x)
- 7.7 Confidence interval for the mean and prediction intervals for a new observation
- 7.8 Chapter summary
- 7.9 Summary of important R code
- 7.10 Practice problems
- 8 Multiple linear regression
- 8.1 Going from SLR to MLR
- 8.2 Validity conditions in MLR
- 8.3 Interpretation of MLR terms
- 8.4 Comparing multiple regression models
- 8.5 General recommendations for MLR interpretations and VIFs
- 8.6 MLR inference: Parameter inferences using the t-distribution
- 8.7 Overall F-test in multiple linear regression
- 8.8 Case study: First year college GPA and SATs
- 8.9 Different intercepts for different groups: MLR with indicator variables
- 8.10 Additive MLR with more than two groups: Headache example
- 8.11 Different slopes and different intercepts
- 8.12 F-tests for MLR models with quantitative and categorical variables and interactions
- 8.13 AICs for model selection
- 8.14 Case study: Forced expiratory volume model selection using AICs
- 8.15 Chapter summary
- 8.16 Summary of important R code
- 8.17 Practice problems
- 9 Case studies
- 9.1 Overview of material covered
- 9.2 The impact of simulated chronic nitrogen deposition on the biomass and N2-fixation activity of two boreal feather moss–cyanobacteria associations
- 9.3 Ants learn to rely on more informative attributes during decision-making
- 9.4 Multi-variate models are essential for understanding vertebrate diversification in deep time
- 9.5 What do didgeridoos really do about sleepiness?
- 9.6 General summary
- References
8.2 Validity conditions in MLR
But before we get too excited about any results, we should always assess our validity conditions. For MLR, they are similar to those for SLR:
Quantitative variables condition:
Independence of observations:
This assumption is about the responses – we must assume that they were collected in a fashion so that they can be assumed to be independent. This implies that we also have independent random errors.
This is not an assumption about the predictor variables!
Linearity of relationship (NEW VERSION FOR MLR!):
Linearity is assumed between the response variable and each explanatory variable (\(y\) and each \(x\)).
We can check this three ways:
Make plots of the response versus each explanatory variable:
- Only visual evidence of a curving relationship is a problem here. Transformations of individual explanatory variables or the response are possible. It is possible to not find a problem in this plot that becomes more obvious when we account for variability that is explained by other variables in the partial residuals.
Examine the Residuals vs Fitted plot:
- When using MLR, curves in the residuals vs. fitted values suggest a missed curving relationship with at least one predictor variable, but it will not be specific as to which one is non-linear. Revisit the scatterplots to identify the source of the issue.
Examine partial residuals and smoothing line in term-plots.
- Turning on the
residuals=Toption in the effects plot allows direct assessment of residuals vs each predictor after accounting for others. Look for clear patterns in the partial residuals116 that the smoothing line is also following for potential issues with the linearity assumption.
- Turning on the
Multicollinearity effects checked for:
Issues here do not mean we cannot proceed with a given model, but it can impact our ability to trust and interpret the estimated terms. Extreme issues might require removing some highly correlated variables prior to really focusing on a model.
Check a scatterplot or correlation matrix to assess the potential for shared information in different predictor variables.
Use the diagnostic measure called a variance inflation factor (VIF) discussed in Section 8.5 (we need to develop some ideas first to understand this measure).
Equal (constant) variance:
- Same as before since it pertains to the residuals.
Normality of residuals:
- Same as before since it pertains to the residuals.
No influential points:
Leverage is now determined by how unusual a point is for multiple explanatory variables.
The leverage values in the Residuals vs Leverage plot are scaled to add up to the degrees of freedom (df) used for the model which is the number of explanatory variables (\(K\)) plus 1, so \(K+1\).
The scale of leverages depends on the complexity of the model through the df and the sample size.
The interpretation is still that the larger the leverage value, the more leverage the point has.
The mean leverage is always (model used df)/n = (K+1)/n – so focus on the values with above average leverage.
- For example, with \(K=3\) and \(n=20\), the average leverage is \(4/20=1/5\).
High leverage points whose response does not follow the pattern defined by the other observations (now based on patterns for multiple \(x\text{'s}\) with the response) will be influential.
Use the Residual’s vs Leverage plot to identify problematic points. Explore further with Cook’s D continuing to provide a measure of the influence of each observation.
- The rules and interpretations for Cook’s D are the same as in SLR (over 0.5 is possibly influential and over 1 is definitely influential).
While not a condition for use of the methods, a note about random assignment and random sampling is useful here in considering the scope of inference of any results. To make inferences about a population, we need to have a representative sample. If we have randomly assigned levels of treatment variables(s), then we can make causal inferences to subjects like those that we could have observed. And if we both have a representative sample and randomization, we can make causal inferences for the population. It is possible to randomly assign levels of variable(s) to subjects and still collect additional information from other explanatory (sometimes called control) variables. The causal interpretations would only be associated with the explanatory variables that were randomly assigned even though the model might contain other variables. Their interpretation still involves noting all the variables included in the model, as demonstrated below. It is even possible to include interactions between randomly assigned variables and other variables – like drug dosage and sex of the subjects. In these cases, causal inference could apply to the treatment levels but noting that the impacts differ based on the non-randomly assigned variable.
For the Snow Depth data, the conditions can be assessed as:
Quantitative variables condition:
- These are all clearly quantitative variables.
Independence of observations:
- The observations are based on a random sample of sites from the population and the sites are spread around the mountains in Montana. Many people would find it to be reasonable to assume that the sites are independent of one another but others would be worried that sites closer together in space might be more similar than they are to far-away observations (this is called spatial correlation). I have been in a heated discussion with statistics colleagues about whether spatial dependency should be considered or if it is valid to ignore it in this sort of situation. It is certainly possible to be concerned about independence of observations here but it takes more advanced statistical methods to actually assess whether there is spatial dependency in these data. Even if you were going to pursue models that incorporate spatial correlations, the first task would be to fit this sort of model and then explore the results. When data are collected across space, you should note that there might be some sort of spatial dependency that could violate the independence assumption.
To assess the remaining assumptions, we can use our diagnostic plots.
The same code
as before will provide diagnostic plots. There is some extra code
(par(...)) added to allow us to add labels to the plots (sub.caption="...") to know which model
is being displayed since we have so many to discuss here. We can also employ a new approach, which is to simulate new observations from the model and make plots to compare simulated data sets to what was observed. The simulate function from Chapter 2 can be used to generate new observations from the model based on the estimated coefficients and where we know that the assumptions are true. If the simulated data and the observed data are very different, then the model is likely dangerous to use for inferences because of this mis-match. This method can be used to assess the linearity, constant variance, normality of residuals, and influential points aspects of the model. It is not something used in every situation, but is especially helpful if you are struggling to decide if what you are seeing in the diagnostics is just random variability or is really a clear issue. The regular steps in assessing each assumption are discussed first.
(ref:fig8-5) Diagnostic plots for model m4: \(\text{Snow.Depth}\sim \text{Elevation} + \text{Min.Temp} + \text{Max.Temp}\).
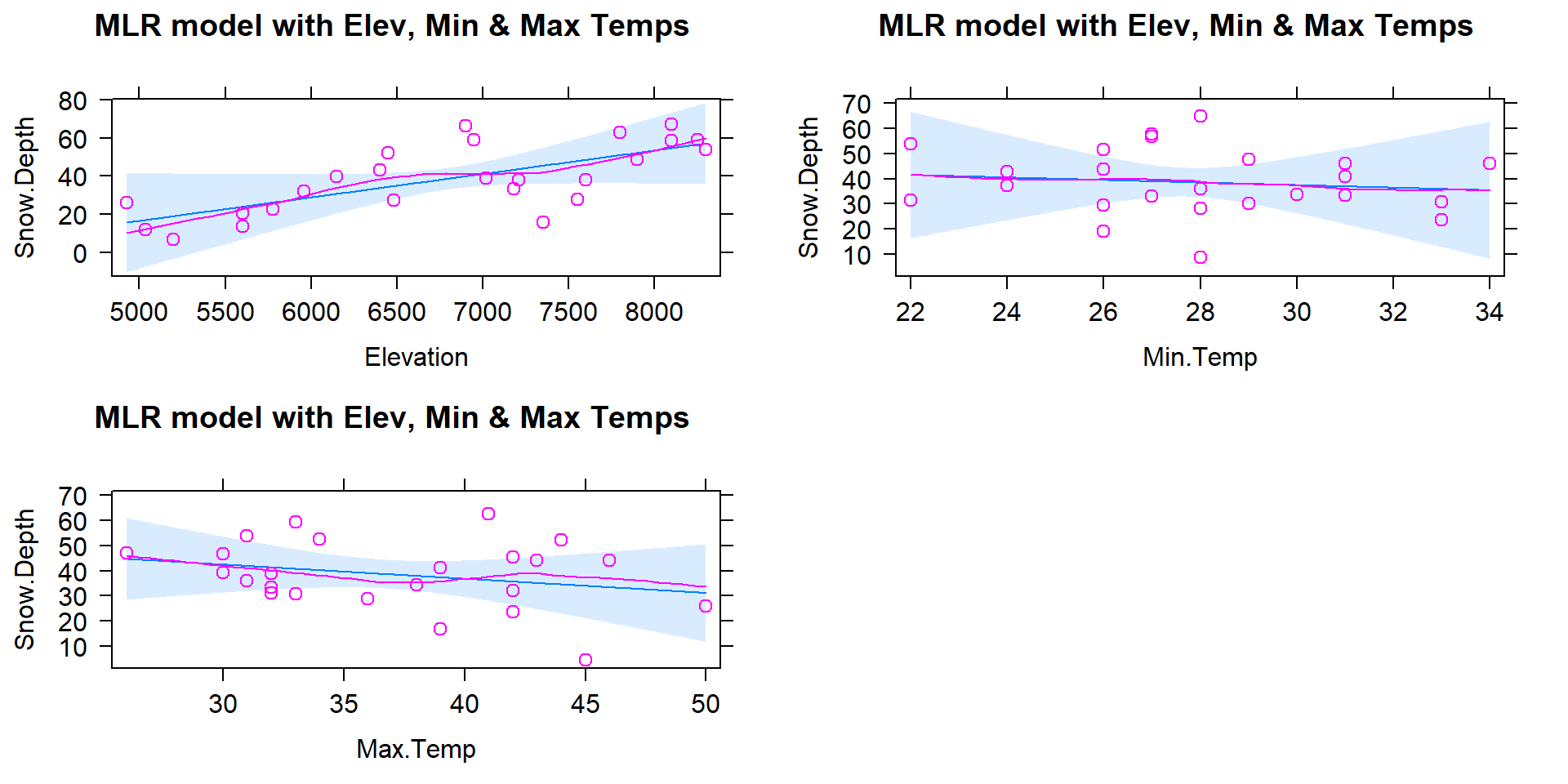
Figure 2.154: (ref:fig8-5)
Linearity of relationship (NEW VERSION FOR MLR!):
Make plots of the response versus each explanatory variable:
- In Figure 2.149, the plots of each variable versus snow depth do not clearly show any nonlinearity except for a little dip around 7000 feet in the plot vs Elevation.
Examine the Residuals vs Fitted plot in Figure 2.154:
- Generally, there is no clear curvature in the Residuals vs Fitted panel and that would be an acceptable answer. However, there is some pattern in the smoothing line that could suggest a more complicated relationship between at least one predictor and the response. This also resembles the pattern in the Elevation vs. Snow depth panel in Figure 2.149 so that might be the source of this “problem”. This suggests that there is the potential to do a little bit better but that it is not unreasonable to proceed on with the MLR, ignoring this little wiggle in the diagnostic plot.
Examine partial residuals as seen in Figure 2.153:
- In the term-plot for elevation from this model, there is a slight pattern in the partial residuals between 6,500 and 7,500 feet. This was also apparent in the original plot and suggests a slight nonlinearity in the pattern of responses versus this explanatory variable.
Multicollinearity effects checked for:
The predictors certainly share information in this application (correlations between -0.67 and -0.91) and multicollinearity looks to be a major concern in being able to understand/separate the impacts of temperatures and elevations on snow depths.
See Section 8.5 for more on this issue in these data.
Equal (constant) variance:
- While there is a little bit more variability in the middle of the fitted values, this is more an artifact of having a smaller data set with a couple of moderate outliers that fell in the same range of fitted values and maybe a little bit of missed curvature. So there is not too much of an issue with this condition.
Normality of residuals:
- The residuals match the normal distribution fairly closely the QQ-plot, showing only a little deviation for observation 9 from a normal distribution and that deviation is extremely minor. There is certainly no indication of a violation of the normality assumption here.
No influential points:
With \(K=3\) predictors and \(n=25\) observations, the average leverage is \(4/25=0.16\). This gives us a scale to interpret the leverage values on the x-axis of the lower right panel of our diagnostic plots.
There are three higher leverage points (leverages over 0.3) with only one being influential (point 9) with Cook’s D close to 1.
- Note that point 10 had the same leverage but was not influential with Cook’s D less than 0.5.
We can explore both of these points to see how two observations can have the same leverage and different amounts of influence.
The two flagged points, observations 9 and 10 in the data set, are for the
sites “Northeast Entrance” (to Yellowstone) and “Combination”. We can use the
MLR equation to do some prediction for each observation and calculate residuals
to see how far the model’s predictions are from the actual observed values for
these sites. For the Northeast Entrance, the Max.Temp was 45, the Min.Temp
was 28, and the Elevation was 7350 as you can see in
this printout of just the two rows of the data set available by referencing
rows 9 and 10 in the bracket from snotel2:
## # A tibble: 2 x 6
## ID Station Max.Temp Min.Temp Elevation Snow.Depth
## <dbl> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 18 Northeast Entrance 45 28 7350 11.2
## 2 53 Combination 36 28 5600 14The estimated Snow Depth for the Northeast Entrance site (observation 9) is found using the estimated model with
\[\begin{array}{rl} \widehat{\text{SnowDepth}}_9 &= -10.51 + 0.0123\cdot\text{Elevation}_9 - 0.505\cdot\text{MinTemp}_9 - 0.562\cdot\text{MaxTemp}_9 \\ & = -10.51 + 0.0123*\boldsymbol{7350} -0.505*\boldsymbol{28} - 0.562*\boldsymbol{45} \\ & = 40.465 \text{ inches,} \end{array}\]
but the observed snow depth was actually \(y_9=11.2\) inches. The observed residual is then
\[e_9=y_9-\hat{y}_9 = 11.2-40.465 = -29.265 \text{ inches.}\]
So the model “misses” the snow depth by over 29 inches with the model suggesting over 40 inches of snow but only 11 inches actually being present117.
## [1] 40.465## [1] -29.265This point is being rated as influential (Cook’s D \(\approx\) 1) with a leverage of nearly 0.35 and a standardized residual (y-axis of Residuals vs. Leverage plot) of nearly -3. This suggests that even with this observation impacting/distorting the slope coefficients (that is what influence means), the model is still doing really poorly at fitting this observation. We’ll drop it and re-fit the model in a second to see how the slopes change. First, let’s compare that result to what happened for data point 10 (“Combination”) which was just as high leverage but not identified as influential.
The estimated snow depth for the Combination site is
\[\begin{array}{rl} \widehat{\text{SnowDepth}}_{10} &= -10.51 + 0.0123\cdot\text{Elevation}_{10} - 0.505\cdot\text{MinTemp}_{10} - 0.562\cdot\text{MaxTemp}_{10} \\ & = -10.51 + 0.0123*\boldsymbol{5600} -0.505*\boldsymbol{28} - 0.562*\boldsymbol{36} \\ & = 23.998 \text{ inches.} \end{array}\]
The observed snow depth here was \(y_{10} = 14.0\) inches so the observed residual is then
\[e_{10}=y_{10}-\hat{y}_{10} = 14.0-23.998 = -9.998 \text{ inches.}\]
This results in a standardized residual of around -1. This is still a “miss” but not as glaring as the previous result and also is not having a major impact on the model’s estimated slope coefficients based on the small Cook’s D value.
## [1] 23.998## [1] -9.998Note that any predictions using this model presume that it is
trustworthy, but
the large Cook’s D on one observation suggests we should consider the model
after removing that observation. We can re-run the model without the
9th observation using the data set snotel2[-9,].
##
## Call:
## lm(formula = Snow.Depth ~ Elevation + Min.Temp + Max.Temp, data = snotel2[-9,
## ])
##
## Residuals:
## Min 1Q Median 3Q Max
## -29.2918 -4.9757 -0.9146 5.4292 20.4260
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -1.424e+02 9.210e+01 -1.546 0.13773
## Elevation 2.141e-02 6.101e-03 3.509 0.00221
## Min.Temp 6.722e-01 1.733e+00 0.388 0.70217
## Max.Temp 5.078e-01 6.486e-01 0.783 0.44283
##
## Residual standard error: 11.29 on 20 degrees of freedom
## Multiple R-squared: 0.7522, Adjusted R-squared: 0.715
## F-statistic: 20.24 on 3 and 20 DF, p-value: 2.843e-06(ref:fig8-6) Term-plots for the MLR for Snow Depth based on Elevation, Min Temp, and Max Temp with Northeast entrance observation removed from data set (n=24).
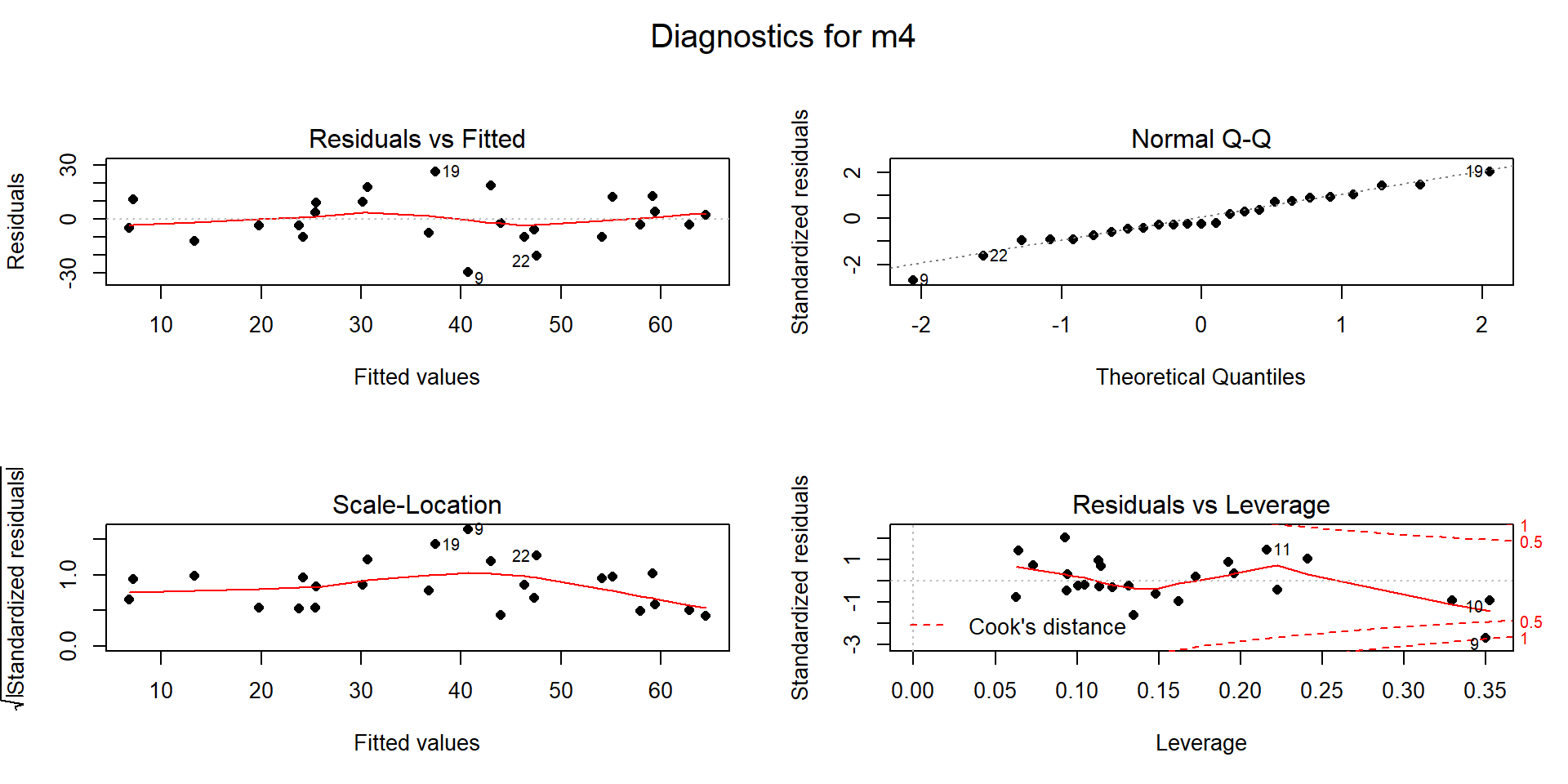
Figure 2.155: (ref:fig8-6)
The estimated MLR model with \(n=24\) after removing the influential “NE Entrance” observation is
\[\widehat{\text{SnowDepth}}_i = -142.4 + 0.0214\cdot\text{Elevation}_i +0.672\cdot\text{MinTemp}_i +0.508\cdot\text{MaxTemp}_i\ .\]
Something unusual has happened here: there is a positive slope for both temperature terms in Figure 2.155 that both contradicts reasonable expectations (warmer temperatures are related to higher snow levels?) and our original SLR results. So what happened? First, removing the influential point has drastically changed the slope coefficients (remember that was the definition of an influential point). Second, when there are predictors that share information, the results can be somewhat unexpected for some or all the predictors when they are all in the model together. Note that the Elevation term looks like what we might expect and seems to have a big impact on the predicted Snow Depths. So when the temperature variables are included in the model they might be functioning to explain some differences in sites that the Elevation term could not explain. This is where our “adjusting for” terminology comes into play. The unusual-looking slopes for the temperature effects can be explained by interpreting them as the estimated change in the response for changes in temperature after we control for the impacts of elevation. Suppose that Elevation explains most of the variation in Snow Depth except for a few sites where the elevation cannot explain all the variability and the site characteristics happen to show higher temperatures and more snow (or lower temperatures and less snow). This could be because warmer areas might have been hit by a recent snow storm while colder areas might have been missed (this is just one day and subject to spatial and temporal fluctuations in precipitation patterns). Or maybe there is another factor related to having marginally warmer temperatures that are accompanied by more snow (maybe the lower snow sites for each elevation were so steep that they couldn’t hold much snow but were also relatively colder?). Thinking about it this way, the temperature model components could provide useful corrections to what Elevation is providing in an overall model and explain more variability than any of the variables could alone. It is also possible that the temperature variables are not needed in a model with Elevation in it, are just “explaining noise”, and should be removed from the model. Each of the next sections take on various aspects of these issues and eventually lead to a general set of modeling and model selection recommendations to help you work in situations as complicated as this. Exploring the results for this model assumes we trust it and, once again, we need to check diagnostics before getting too focused on any particular results from it.
The Residuals vs. Leverage diagnostic plot in Figure 2.156 for the model fit to the data set without NE Entrance (now \(n=24\)) reveals a new point that is somewhat influential (point 22 in the data set has Cook’s D \(\approx\) 0.5). It is for a location called "Bloody \(\require{color}\colorbox{black}{Redact.}\)118 which has a leverage of nearly 0.2 and a standardized residual of nearly -3. This point did not show up as influential in the original version of the data set with the same model but it is now. It also shows up as a potential outlier. As we did before, we can explore it a bit by comparing the model predicted snow depth to the observed snow depth. The predicted snow depth for this site (see output below for variable values) is
\[\widehat{\text{SnowDepth}}_{22} = -142.4 + 0.0214*\boldsymbol{7550} +0.672*\boldsymbol{26} +0.508*\boldsymbol{39} = 56.45 \text{ inches.}\]
The observed snow depth was 27.2 inches, so the estimated residual is -39.25 inches. Again, this point is potentially influential and an outlier. Additionally, our model contains results that are not what we would have expected a priori, so it is not unreasonable to consider removing this observation to be able to work towards a model that is fully trustworthy.
(ref:fig8-7) Diagnostic plots for MLR for Snow Depth based on Elevation, Min Temp and Max Temp with Northeast entrance observation removed from data set.
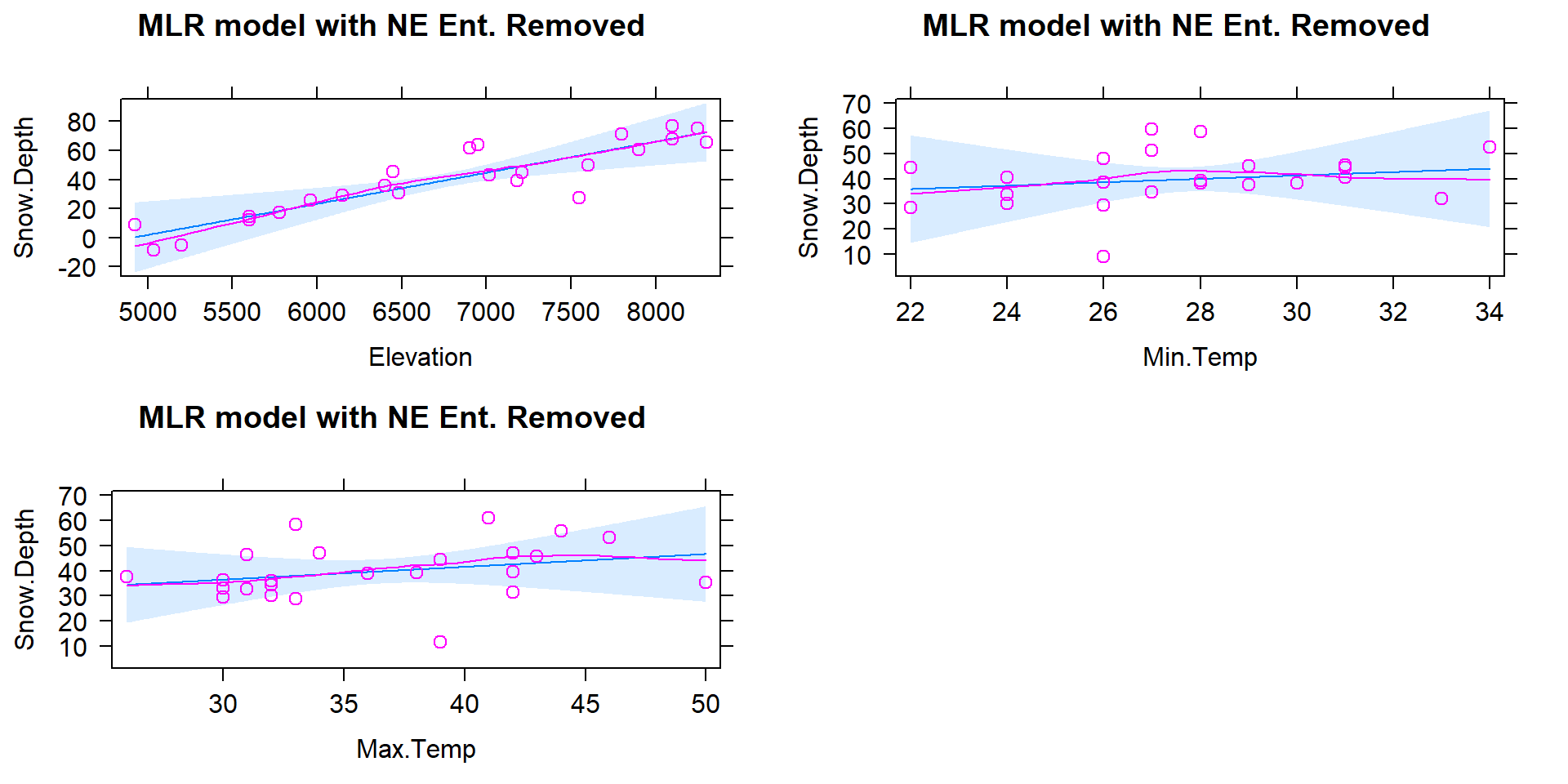
Figure 2.156: (ref:fig8-7)
(ref:fig8-8) Diagnostic plots for MLR for Snow Depth based on Elevation, Min Temp and Max Temp with two observations removed (\(n=23\)).
##
## Call:
## lm(formula = Snow.Depth ~ Elevation + Min.Temp + Max.Temp, data = snotel2[-c(9,
## 22), ])
##
## Residuals:
## Min 1Q Median 3Q Max
## -14.878 -4.486 0.024 3.996 20.728
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -2.133e+02 7.458e+01 -2.859 0.0100
## Elevation 2.686e-02 4.997e-03 5.374 3.47e-05
## Min.Temp 9.843e-01 1.359e+00 0.724 0.4776
## Max.Temp 1.243e+00 5.452e-01 2.280 0.0343
##
## Residual standard error: 8.832 on 19 degrees of freedom
## Multiple R-squared: 0.8535, Adjusted R-squared: 0.8304
## F-statistic: 36.9 on 3 and 19 DF, p-value: 4.003e-08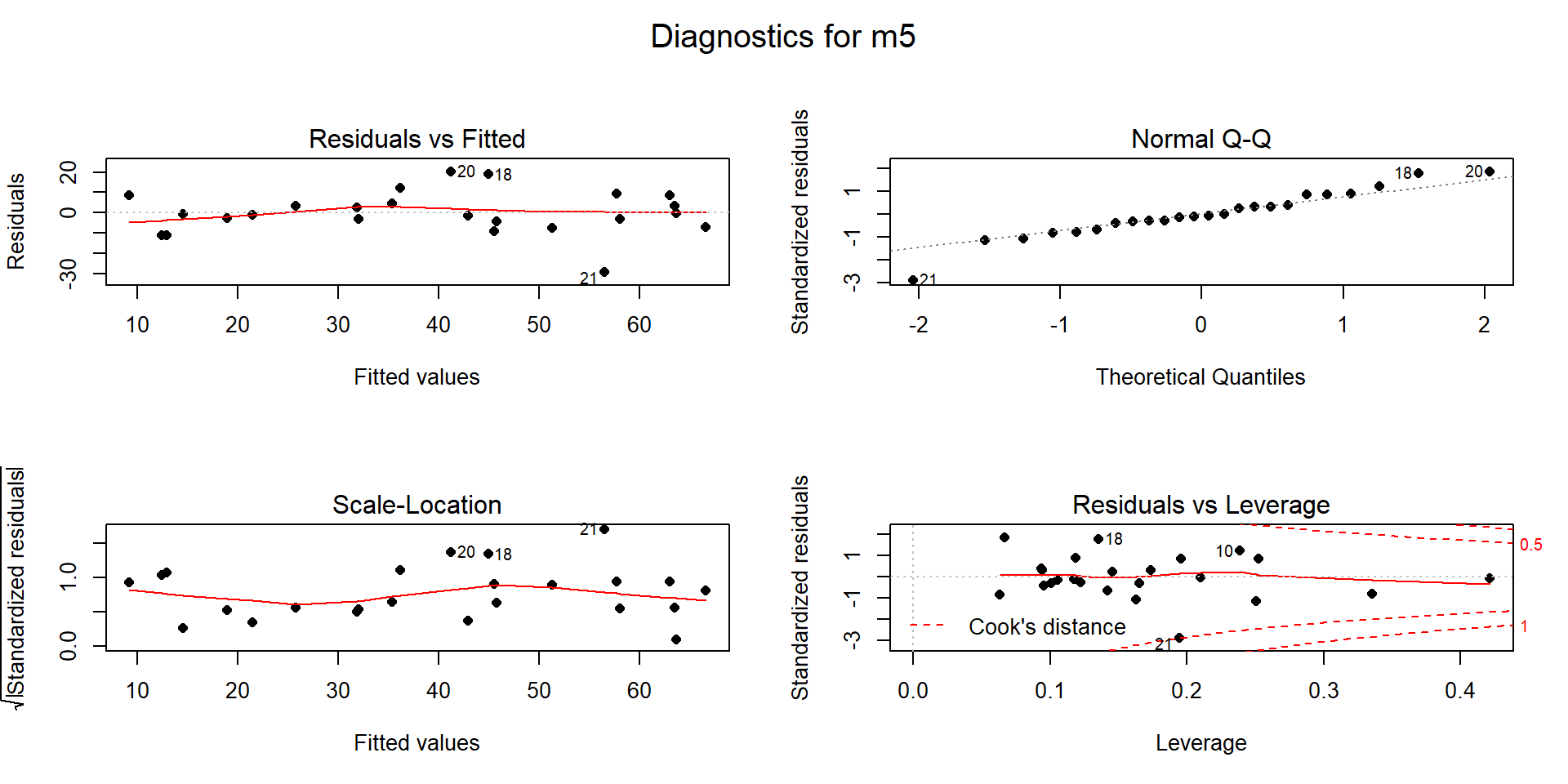
Figure 2.157: (ref:fig8-8)
This worry-some observation is located in the 22nd row of the original data set:
## # A tibble: 1 x 6
## ID Station Max.Temp Min.Temp Elevation Snow.Depth
## <dbl> <fct> <dbl> <dbl> <dbl> <dbl>
## 1 36 Bloody [Redact.] 39 26 7550 27.2With the removal of both the “Northeast Entrance” and “Bloody
\(\require{color}\colorbox{black}{Redact.}\)” sites, there are \(n=23\) observations
remaining. This model (m6) seems to contain residual diagnostics (Figure
2.157) that are finally generally reasonable.
m6 <- lm(Snow.Depth~Elevation+Min.Temp+Max.Temp, data=snotel2[-c(9,22),])
summary(m6)
par(mfrow=c(2,2), oma=c(0,0,2,0))
plot(m6, sub.caption="Diagnostics for m6", pch=16)It is hard to suggest that there any curvature issues and the slight variation in the Scale-Location plot is mostly due to few observations with fitted values around 30 happening to be well approximated by the model. The normality assumption is generally reasonable and no points seem to be overly influential on this model (finally!).
The term-plots (Figure 2.158) show that the temperature slopes are both positive although in this model Max.Temp seems to be more “important” than Min.Temp. We have ruled out individual influential points as the source of un-expected directions in slope coefficients and the more likely issue is multicollinearity – in a model that includes Elevation, the temperature effects may be positive, again acting with the Elevation term to generate the best possible predictions of the observed responses. Throughout this discussion, we have mainly focused on the slope coefficients and diagnostics. We have other tools in MLR to more quantitatively assess and compare different regression models that are considered in the next sections.
(ref:fig8-9) Term-plots for the MLR for Snow Depth based on Elevation, Min Temp and Max Temp with two observations removed.
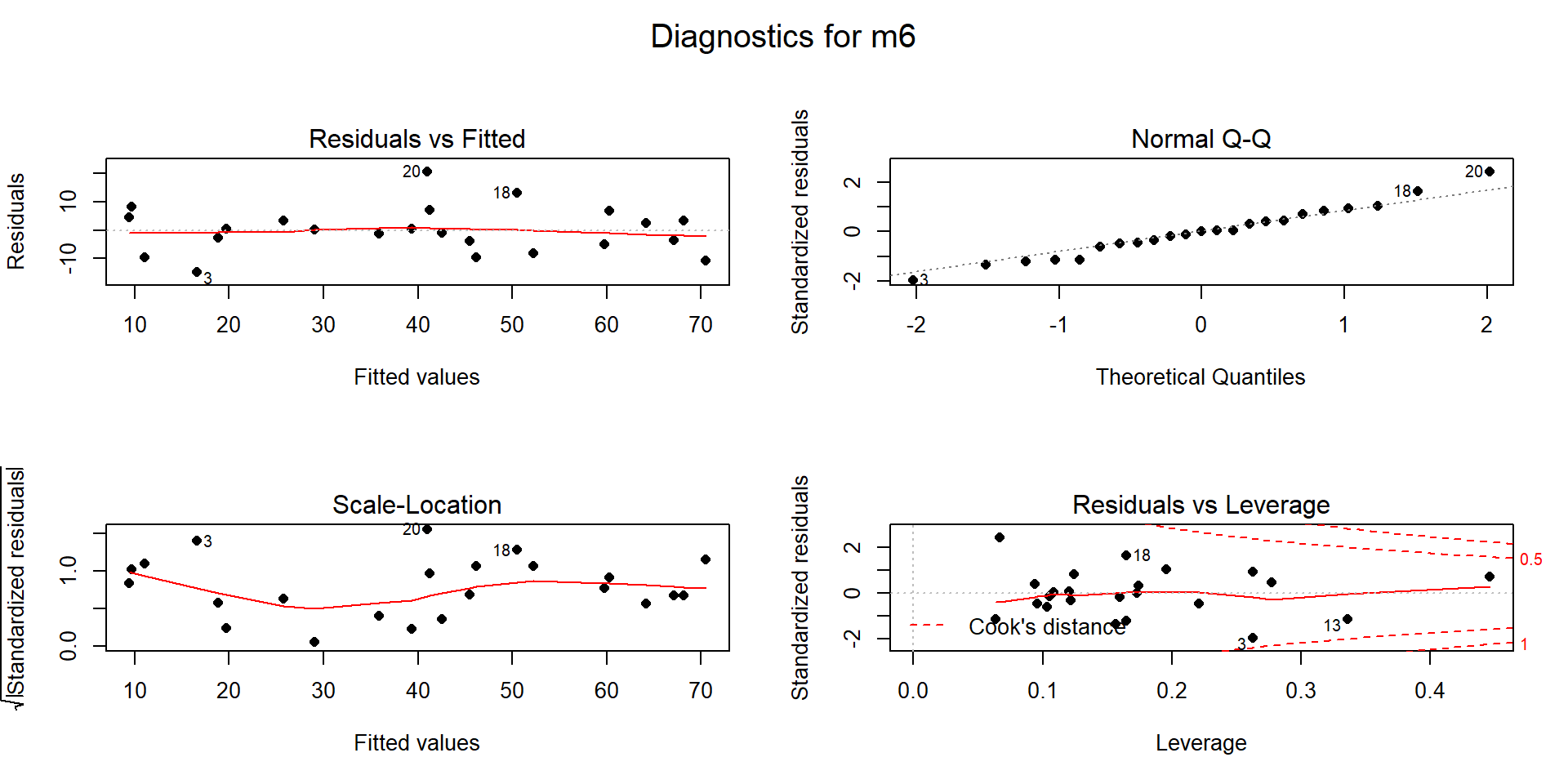
Figure 2.158: (ref:fig8-9)
As a final assessment of this model, we can consider simulating a set of \(n=23\) responses from this model and then comparing that data set to the one we just analyzed. This does not change the predictor variables, but creates a new response that is called SimulatedSnow in the following codechunk. Figure 2.159 uses the plot function to just focus on the relationship of the original (Snow.Depth) and new (fake) responses (SimulatedSnow) versus each of the predictors. In exploring two realizations of simulated responses from the model, the results look fairly similar to the original data set. This model appeared to have reasonable assumptions for the match between simulated responses and the original ones reinforces those previous assessments. When the match is not so close, it can reinforce or create concern about the way that the assumptions have been assessed using other tools.
set.seed(307)
snotel_final <- snotel2[-c(9,22),]
snotel_final$SimulatedSnow <- simulate(m6)[[1]] #Creates first set of simulated responses
par(mfrow=c(3,3))
plot(Snow.Depth~Elevation + Max.Temp + Min.Temp, data=snotel_final, pch=16, main="Real Responses")
plot(SimulatedSnow~Elevation + Max.Temp + Min.Temp, data=snotel_final, pch=17, main="First Simulated Responses", col="darkgreen")
snotel_final$SimulatedSnow <- simulate(m6)[[1]] #Creates a second set of simulared responses in the same variable name
plot(SimulatedSnow~Elevation + Max.Temp + Min.Temp, data=snotel_final, pch=16, main="Second Simulated Responses", col="skyblue")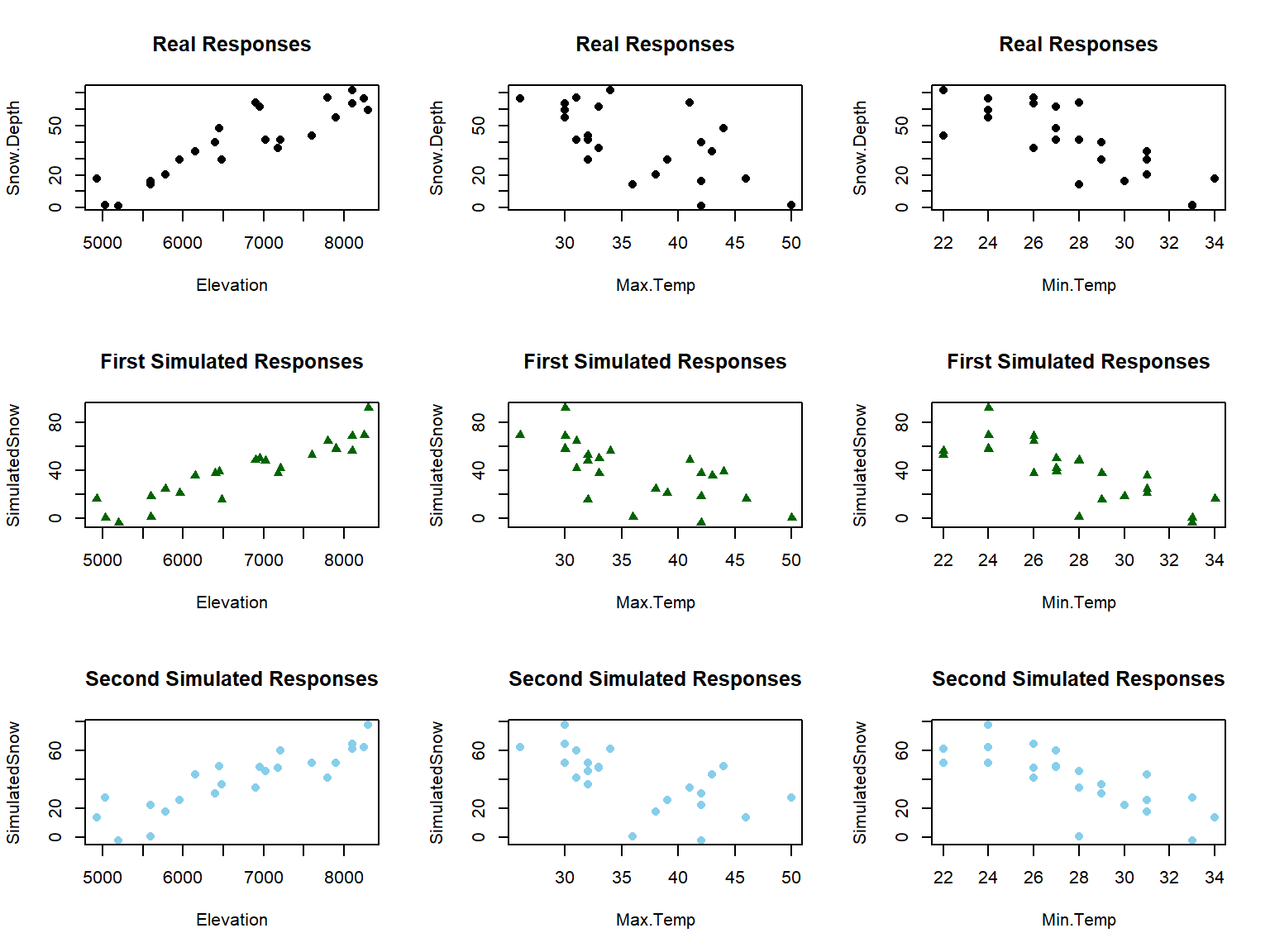
Figure 2.159: Plot of the original responses versus the three predictors (\(n\)=23 data set) in the top row and two sets of simulated responses versus the predictors in the bottom two rows.
I have not given you a formula for calculating partial residuals. We will leave that for more advanced material.↩
Imagine showing up to a ski area expecting a 40 inch base and there only being 11 inches. I’m sure ski areas are always more accurate than this model in their reporting of amounts of snow on the ground…↩
The site name is redacted to protect the innocence of the reader. More information on this site, located in Beaverhead County, is available at http://www.wcc.nrcs.usda.gov/nwcc/site?sitenum=355&state=mt.↩