- Cover
- Acknowledgments
- 1 Preface
- 2 (R)e-Introduction to statistics
- 2.1 Histograms, boxplots, and density curves
- 2.2 Pirate-plots
- 2.3 Models, hypotheses, and permutations for the two sample mean situation
- 2.4 Permutation testing for the two sample mean situation
- 2.5 Hypothesis testing (general)
- 2.6 Connecting randomization (nonparametric) and parametric tests
- 2.7 Second example of permutation tests
- 2.8 Reproducibility Crisis: Moving beyond p < 0.05, publication bias, and multiple testing issues
- 2.9 Confidence intervals and bootstrapping
- 2.10 Bootstrap confidence intervals for difference in GPAs
- 2.11 Chapter summary
- 2.12 Summary of important R code
- 2.13 Practice problems
- 3 One-Way ANOVA
- 3.1 Situation
- 3.2 Linear model for One-Way ANOVA (cell-means and reference-coding)
- 3.3 One-Way ANOVA Sums of Squares, Mean Squares, and F-test
- 3.4 ANOVA model diagnostics including QQ-plots
- 3.5 Guinea pig tooth growth One-Way ANOVA example
- 3.6 Multiple (pair-wise) comparisons using Tukey’s HSD and the compact letter display
- 3.7 Pair-wise comparisons for the Overtake data
- 3.8 Chapter summary
- 3.9 Summary of important R code
- 3.10 Practice problems
- 4 Two-Way ANOVA
- 4.1 Situation
- 4.2 Designing a two-way experiment and visualizing results
- 4.3 Two-Way ANOVA models and hypothesis tests
- 4.4 Guinea pig tooth growth analysis with Two-Way ANOVA
- 4.5 Observational study example: The Psychology of Debt
- 4.6 Pushing Two-Way ANOVA to the limit: Un-replicated designs and Estimability
- 4.7 Chapter summary
- 4.8 Summary of important R code
- 4.9 Practice problems
- 5 Chi-square tests
- 5.1 Situation, contingency tables, and tableplots
- 5.2 Homogeneity test hypotheses
- 5.3 Independence test hypotheses
- 5.4 Models for R by C tables
- 5.5 Permutation tests for the \(X^2\) statistic
- 5.6 Chi-square distribution for the \(X^2\) statistic
- 5.7 Examining residuals for the source of differences
- 5.8 General protocol for \(X^2\) tests
- 5.9 Political party and voting results: Complete analysis
- 5.10 Is cheating and lying related in students?
- 5.11 Analyzing a stratified random sample of California schools
- 5.12 Chapter summary
- 5.13 Summary of important R commands
- 5.14 Practice problems
- 6 Correlation and Simple Linear Regression
- 6.1 Relationships between two quantitative variables
- 6.2 Estimating the correlation coefficient
- 6.3 Relationships between variables by groups
- 6.4 Inference for the correlation coefficient
- 6.5 Are tree diameters related to tree heights?
- 6.6 Describing relationships with a regression model
- 6.7 Least Squares Estimation
- 6.8 Measuring the strength of regressions: R2
- 6.9 Outliers: leverage and influence
- 6.10 Residual diagnostics – setting the stage for inference
- 6.11 Old Faithful discharge and waiting times
- 6.12 Chapter summary
- 6.13 Summary of important R code
- 6.14 Practice problems
- 7 Simple linear regression inference
- 7.1 Model
- 7.2 Confidence interval and hypothesis tests for the slope and intercept
- 7.3 Bozeman temperature trend
- 7.4 Randomization-based inferences for the slope coefficient
- 7.5 Transformations part I: Linearizing relationships
- 7.6 Transformations part II: Impacts on SLR interpretations: log(y), log(x), & both log(y) & log(x)
- 7.7 Confidence interval for the mean and prediction intervals for a new observation
- 7.8 Chapter summary
- 7.9 Summary of important R code
- 7.10 Practice problems
- 8 Multiple linear regression
- 8.1 Going from SLR to MLR
- 8.2 Validity conditions in MLR
- 8.3 Interpretation of MLR terms
- 8.4 Comparing multiple regression models
- 8.5 General recommendations for MLR interpretations and VIFs
- 8.6 MLR inference: Parameter inferences using the t-distribution
- 8.7 Overall F-test in multiple linear regression
- 8.8 Case study: First year college GPA and SATs
- 8.9 Different intercepts for different groups: MLR with indicator variables
- 8.10 Additive MLR with more than two groups: Headache example
- 8.11 Different slopes and different intercepts
- 8.12 F-tests for MLR models with quantitative and categorical variables and interactions
- 8.13 AICs for model selection
- 8.14 Case study: Forced expiratory volume model selection using AICs
- 8.15 Chapter summary
- 8.16 Summary of important R code
- 8.17 Practice problems
- 9 Case studies
- 9.1 Overview of material covered
- 9.2 The impact of simulated chronic nitrogen deposition on the biomass and N2-fixation activity of two boreal feather moss–cyanobacteria associations
- 9.3 Ants learn to rely on more informative attributes during decision-making
- 9.4 Multi-variate models are essential for understanding vertebrate diversification in deep time
- 9.5 What do didgeridoos really do about sleepiness?
- 9.6 General summary
- References
7.4 Randomization-based inferences for the slope coefficient
Exploring permutation testing in SLR provides an opportunity to gauge the observed
relationship against the sorts of relationships we would expect to see if there
was no linear relationship between the variables. If the relationship is linear
(not curvilinear) and the null hypothesis of \(\beta_1=0\) is true, then any
configuration of the responses relative to the
predictor variable’s values is as good as any other.
Consider the four scatterplots of
the Bozeman temperature data versus Year and permuted versions of Year
in Figure 2.131. First, think about which of the panels you
think present the most
evidence of a linear relationship between Year and Temperature?
(ref:fig7-8) Plot of the Temperature responses versus four versions of
Year, three of which are permutations of the Year variable relative
to the Temperatures.
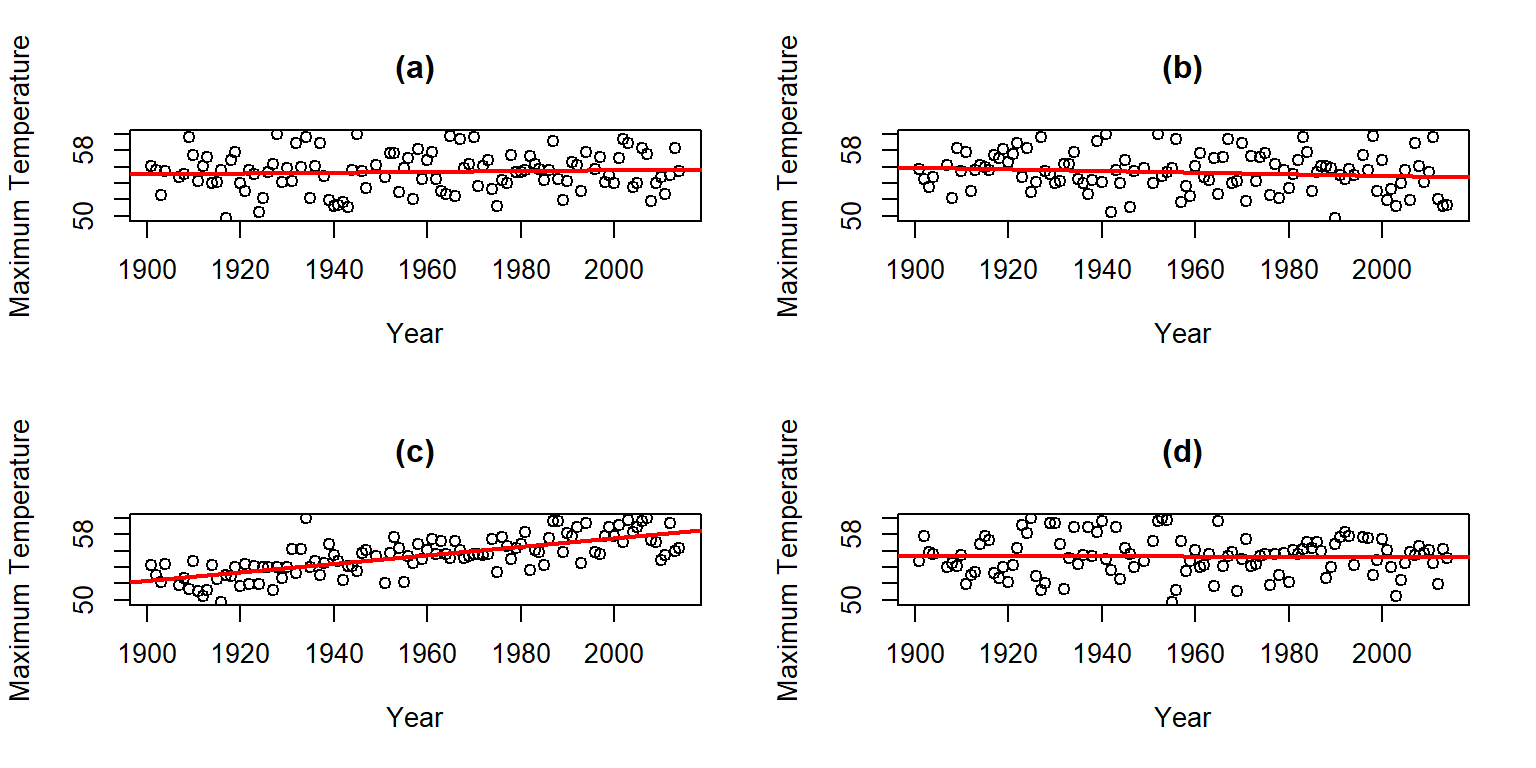
Figure 2.132: (ref:fig7-8)
Hopefully you can see that panel (c) contains the most clear linear relationship among the choices. The plot in panel (c) is actually the real data set and pretty clearly presents itself as “different” from the other results. When we have small p-values, the real data set will be clearly different from the permuted results because it will be almost impossible to find a permuted data set that can attain as large a slope coefficient as was observed in the real data set105. This result ties back into our original interests in this climate change research situation – does our result look like it is different from what could have been observed just by chance if there were no linear relationship between \(x\) and \(y\)? It seems unlikely…
Repeating this permutation process and tracking the estimated slope coefficients, as \(T^*\), provides another method to obtain a p-value in SLR applications. This could also be performed on the \(t\)-statistic for the slope coefficient and would provide the same p-values but the sampling distribution would have a different x-axis scaling. In this situation, the observed slope of 0.052 is really far from any possible values that can be obtained using permutations as shown in Figure 2.133. The p-value would be reported as \(<0.001\) for the two-sided permutation test.
## Year
## 0.05244213(ref:fig7-9) Permutation distribution of the slope coefficient in the Bozeman temperature linear regression model with bold vertical lines at \(\pm b_1=0.56\) based on the observed estimated slope.
for (b in (1:B)){
Tstar[b] <- lm(meanmax~shuffle(Year), data=bozemantemps)$coef[2]
}
pdata(abs(Tstar), abs(Tobs), lower.tail=F)[[1]]## [1] 0par(mfrow=c(1,2))
hist(Tstar, xlim=c(-1,1)*Tobs)
abline(v=c(-1,1)*Tobs, col="red", lwd=3)
plot(density(Tstar), main="Density curve of Tstar", xlim=c(-1,1)*Tobs)
abline(v=c(-1,1)*Tobs, col="red", lwd=3)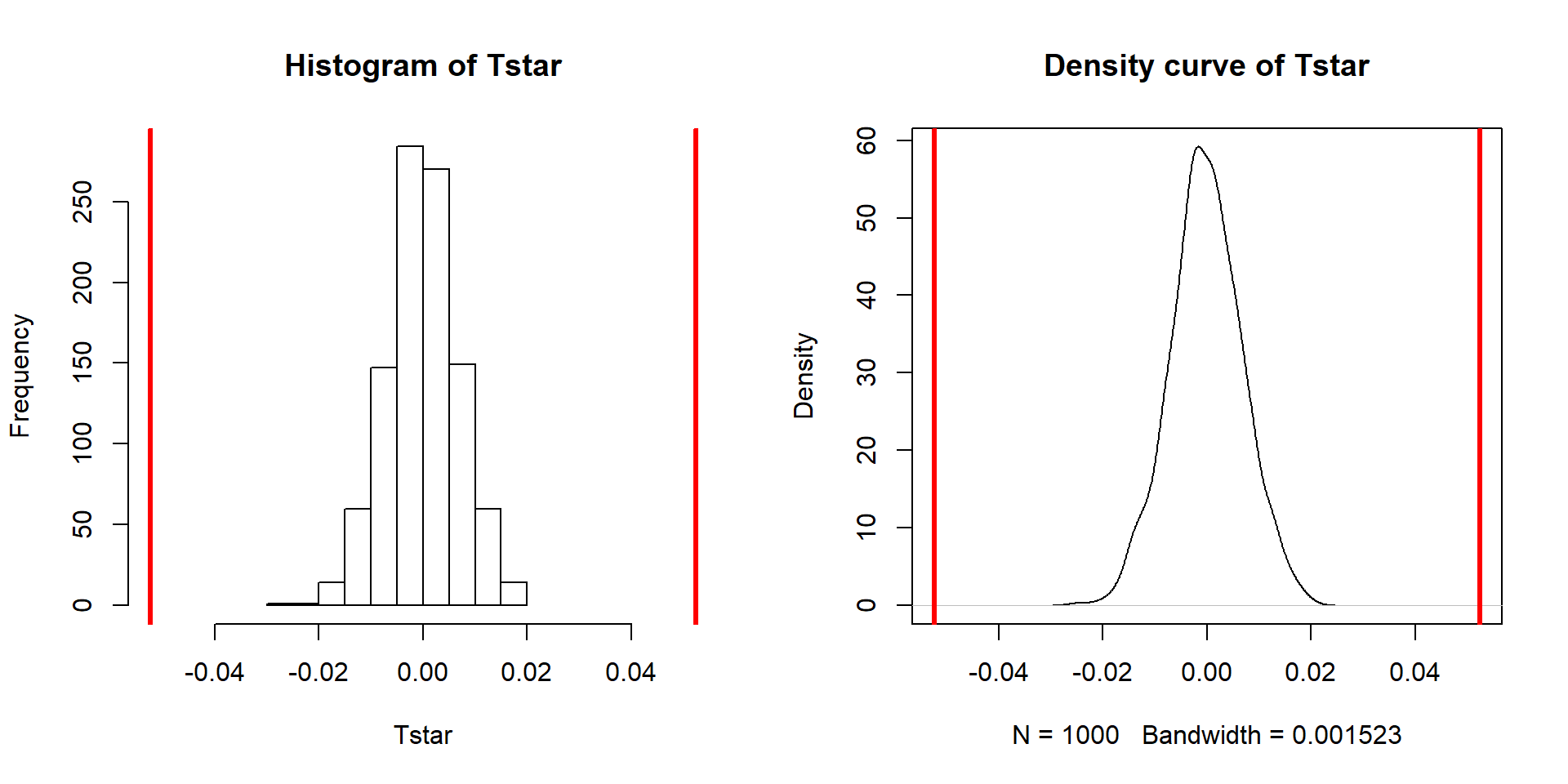
Figure 2.133: (ref:fig7-9)
One other interesting aspect of exploring the permuted data sets as in Figure 2.132 is that the outlier in the late 1930s “disappears” in the permuted data sets because there were many other observations that were that warm, just none that happened around that time of the century in the real data set. This reinforces the evidence for changes over time that seem to be present in these data – old unusual years don’t look unusual in more recent years (which is a pretty concerning result).
The permutation approach can be useful in situations where the normality assumption is compromised, but there are no influential points. In these situations, we might find more trustworthy p-values using permutations but only if we are working with an initial estimated regression equation that we generally trust. I personally like the permutation approach as a way of explaining what a p-value is actually measuring – the chance of seeing something like what we saw, or more extreme, if the null is true. And the previous scatterplots show what the “by chance” versions of this relationship might look like.
In a similar situation where we want to focus on confidence intervals for slope coefficients but are not completely comfortable with the normality assumption, it is also possible to generate bootstrap confidence intervals by sampling with replacement from the data set. This idea was introduced in Sections 2.8 and 2.9. This provides a 95% bootstrap confidence interval from 0.433 to 0.61, which almost exactly matches the parametric \(t\)-based confidence interval. The bootstrap distributions are very symmetric (Figure 2.134). The interpretation is the same and this result reinforces the other assessments that the parametric approach is not unreasonable here except possibly for the independence assumption. These randomization approaches provide no robustness against violations of the independence assumption.
(ref:fig7-10) Bootstrap distribution of the slope coefficient in the Bozeman temperature linear regression model with bold vertical lines delineating the 95% confidence interval and observed slope of 0.52.
## Year
## 0.05244213B <- 1000
Tstar <- matrix(NA, nrow=B)
for (b in (1:B)){
Tstar[b] <- lm(meanmax~Year, data=resample(bozemantemps))$coef[2]
}
quantiles <- qdata(Tstar, c(0.025,0.975))
quantiles## quantile p
## 2.5% 0.04326952 0.025
## 97.5% 0.06131044 0.975par(mfrow=c(1,2))
hist(Tstar, labels=T, ylim=c(0,200))
abline(v=Tobs, col="red", lwd=2)
abline(v=quantiles$quantile, col="blue", lwd=3)
plot(density(Tstar), main="Density curve of Tstar")
abline(v=Tobs, col="red", lwd=2)
abline(v=quantiles$quantile, col="blue", lwd=3)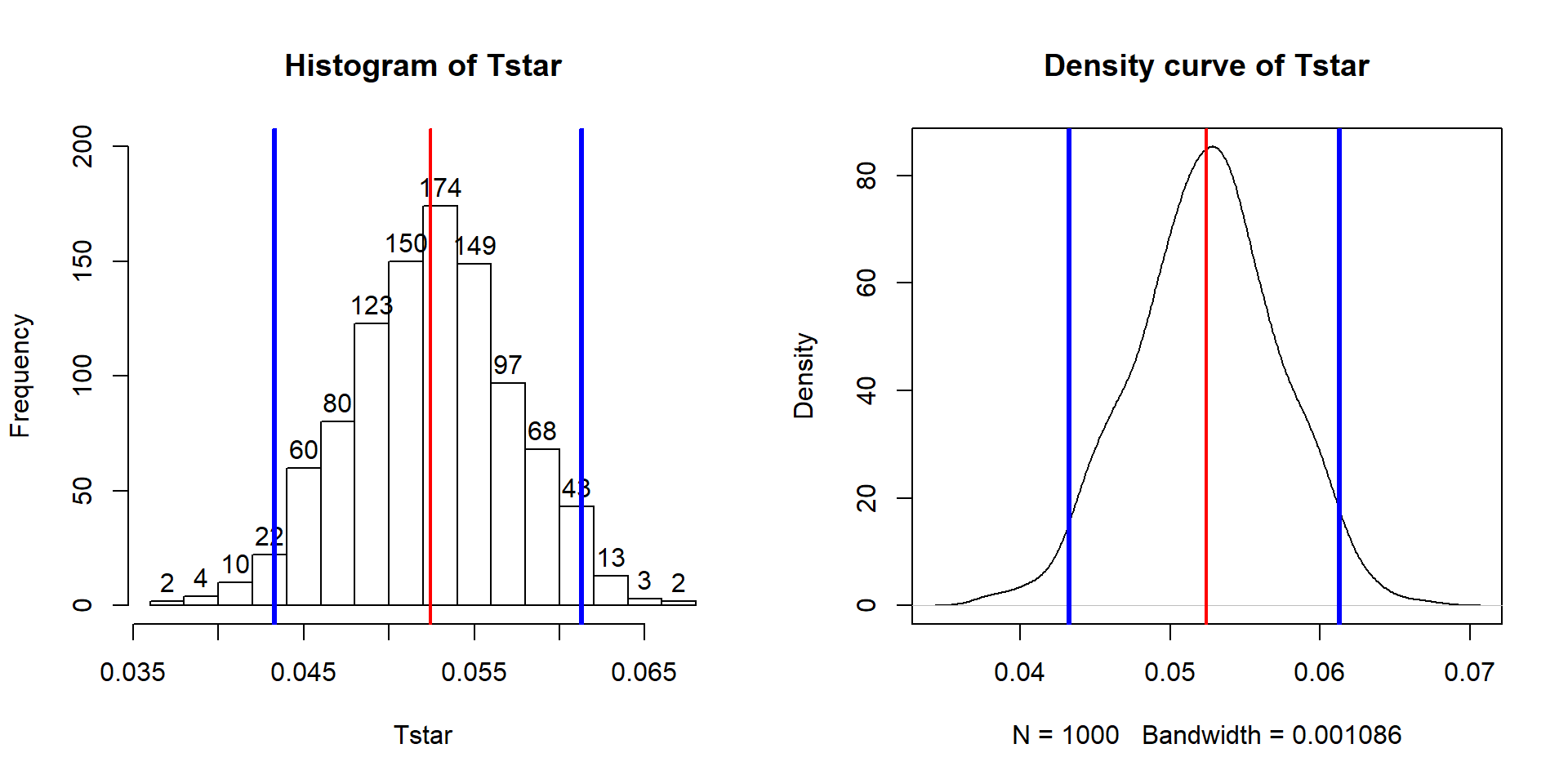
Figure 2.134: (ref:fig7-10)
It took many permutations to get competitor plots this close to the real data set and they really aren’t that close.↩