- Cover
- Acknowledgments
- 1 Preface
- 2 (R)e-Introduction to statistics
- 2.1 Histograms, boxplots, and density curves
- 2.2 Pirate-plots
- 2.3 Models, hypotheses, and permutations for the two sample mean situation
- 2.4 Permutation testing for the two sample mean situation
- 2.5 Hypothesis testing (general)
- 2.6 Connecting randomization (nonparametric) and parametric tests
- 2.7 Second example of permutation tests
- 2.8 Reproducibility Crisis: Moving beyond p < 0.05, publication bias, and multiple testing issues
- 2.9 Confidence intervals and bootstrapping
- 2.10 Bootstrap confidence intervals for difference in GPAs
- 2.11 Chapter summary
- 2.12 Summary of important R code
- 2.13 Practice problems
- 3 One-Way ANOVA
- 3.1 Situation
- 3.2 Linear model for One-Way ANOVA (cell-means and reference-coding)
- 3.3 One-Way ANOVA Sums of Squares, Mean Squares, and F-test
- 3.4 ANOVA model diagnostics including QQ-plots
- 3.5 Guinea pig tooth growth One-Way ANOVA example
- 3.6 Multiple (pair-wise) comparisons using Tukey’s HSD and the compact letter display
- 3.7 Pair-wise comparisons for the Overtake data
- 3.8 Chapter summary
- 3.9 Summary of important R code
- 3.10 Practice problems
- 4 Two-Way ANOVA
- 4.1 Situation
- 4.2 Designing a two-way experiment and visualizing results
- 4.3 Two-Way ANOVA models and hypothesis tests
- 4.4 Guinea pig tooth growth analysis with Two-Way ANOVA
- 4.5 Observational study example: The Psychology of Debt
- 4.6 Pushing Two-Way ANOVA to the limit: Un-replicated designs and Estimability
- 4.7 Chapter summary
- 4.8 Summary of important R code
- 4.9 Practice problems
- 5 Chi-square tests
- 5.1 Situation, contingency tables, and tableplots
- 5.2 Homogeneity test hypotheses
- 5.3 Independence test hypotheses
- 5.4 Models for R by C tables
- 5.5 Permutation tests for the \(X^2\) statistic
- 5.6 Chi-square distribution for the \(X^2\) statistic
- 5.7 Examining residuals for the source of differences
- 5.8 General protocol for \(X^2\) tests
- 5.9 Political party and voting results: Complete analysis
- 5.10 Is cheating and lying related in students?
- 5.11 Analyzing a stratified random sample of California schools
- 5.12 Chapter summary
- 5.13 Summary of important R commands
- 5.14 Practice problems
- 6 Correlation and Simple Linear Regression
- 6.1 Relationships between two quantitative variables
- 6.2 Estimating the correlation coefficient
- 6.3 Relationships between variables by groups
- 6.4 Inference for the correlation coefficient
- 6.5 Are tree diameters related to tree heights?
- 6.6 Describing relationships with a regression model
- 6.7 Least Squares Estimation
- 6.8 Measuring the strength of regressions: R2
- 6.9 Outliers: leverage and influence
- 6.10 Residual diagnostics – setting the stage for inference
- 6.11 Old Faithful discharge and waiting times
- 6.12 Chapter summary
- 6.13 Summary of important R code
- 6.14 Practice problems
- 7 Simple linear regression inference
- 7.1 Model
- 7.2 Confidence interval and hypothesis tests for the slope and intercept
- 7.3 Bozeman temperature trend
- 7.4 Randomization-based inferences for the slope coefficient
- 7.5 Transformations part I: Linearizing relationships
- 7.6 Transformations part II: Impacts on SLR interpretations: log(y), log(x), & both log(y) & log(x)
- 7.7 Confidence interval for the mean and prediction intervals for a new observation
- 7.8 Chapter summary
- 7.9 Summary of important R code
- 7.10 Practice problems
- 8 Multiple linear regression
- 8.1 Going from SLR to MLR
- 8.2 Validity conditions in MLR
- 8.3 Interpretation of MLR terms
- 8.4 Comparing multiple regression models
- 8.5 General recommendations for MLR interpretations and VIFs
- 8.6 MLR inference: Parameter inferences using the t-distribution
- 8.7 Overall F-test in multiple linear regression
- 8.8 Case study: First year college GPA and SATs
- 8.9 Different intercepts for different groups: MLR with indicator variables
- 8.10 Additive MLR with more than two groups: Headache example
- 8.11 Different slopes and different intercepts
- 8.12 F-tests for MLR models with quantitative and categorical variables and interactions
- 8.13 AICs for model selection
- 8.14 Case study: Forced expiratory volume model selection using AICs
- 8.15 Chapter summary
- 8.16 Summary of important R code
- 8.17 Practice problems
- 9 Case studies
- 9.1 Overview of material covered
- 9.2 The impact of simulated chronic nitrogen deposition on the biomass and N2-fixation activity of two boreal feather moss–cyanobacteria associations
- 9.3 Ants learn to rely on more informative attributes during decision-making
- 9.4 Multi-variate models are essential for understanding vertebrate diversification in deep time
- 9.5 What do didgeridoos really do about sleepiness?
- 9.6 General summary
- References
7.1 Model
In Chapter ??, we learned how to estimate and interpret correlations and regression equations with a single predictor variable (simple linear regression or SLR). We carefully explored the variety of things that could go wrong and how to check for problems in regression situations. In this chapter, that work provides the basis for performing statistical inference that mainly focuses on the population slope coefficient based on the sample slope coefficient. As a reminder, the estimated regression model is \(\hat{y}_i = b_0 + b_1x_i\). The population regression equation is \(y_i = \beta_0 + \beta_1x_i + \varepsilon_i\) where \(\beta_0\) is the population (or true) y-intercept and \(\beta_1\) is the population (or true) slope coefficient. These are population parameters (fixed but typically unknown). This model can be re-written to think about different components and their roles. The mean of a random variable is statistically denoted as \(E(y_i)\), the expected value of \(\mathbf{y_i}\), or as \(\mu_{y_i}\) and the mean of the response variable in a simple linear model is specified by \(E(y_i) = \mu_{y_i} = \beta_0 + \beta_1x_i\). This uses the true regression line to define the model for the mean of the responses as a function of the value of the explanatory variable100.
The other part of any statistical model is specifying a model for the variability around the mean. There are two aspects to the variability to specify here – the shape of the distribution and the spread of the distribution. This is where the normal distribution and our “normality assumption” re-appears. And for normal distributions, we need to define a variance parameter, \(\sigma^2\). Combined, the complete regression model is
\[y_i \sim N(\mu_{y_i},\sigma^2), \text{ with } \mu_{y_i} = \beta_0 + \beta_1x_i,\]
which can be read as “y follows a normal distribution with mean mu-y and variance sigma-squared” and that “mu-y is equal to beta-0 plus beta-1 times x”. This also implies that the random variability around the true mean, the errors, follow a normal distribution with mean 0 and that same variance, \(\varepsilon_i \sim N(0,\sigma^2)\). The true deviations (\(\varepsilon_i\)) are once again estimated by the residuals, \(e_i = y_i - \hat{y}_i\) = observed response – predicted response. We can use the residuals to estimate \(\sigma\), which is also called the residual standard error, \(\hat{\sigma} = \sqrt{\Sigma e^2_i / (n-2)}\). We will find this quantity near the end of the regression output as discussed below so the formula is not heavily used here. This provides us with the three parameters that are estimated as part of our SLR model: \(\beta_0, \beta_1,\text{ and } \sigma\).
These definitions also formalize the assumptions implicit in the regression model:
The errors follow a normal distribution (Normality assumption).
The errors have the same variance (Constant variance assumption).
The observations are independent (Independence assumption).
The model for the mean is “correct” (Linearity, No Influential points, Only one group).
The diagnostics described at the end of Chapter ?? provide techniques for checking these assumptions – at least not having clear issues with those assumptions is fundamental to having a regression line that we trust and inferences from it that we also can trust.
To make this clearer, suppose that in the Beers and BAC study that they had randomly assigned 20 students to consume each number of beers. We would expect some variation in the BAC for each group of 20 at each level of Beers but that each group of observations will be centered at the true mean BAC for each number of Beers. The regression model assumes that the BAC values are normally distributed around the mean for each Beer level, \(\text{BAC}_i \sim N(\beta_0 + \beta_1\text{ Beers}_i,\sigma^2)\), with the mean defined by the regression equation. We actually do not need to obtain more than one observation at each \(x\) value to make this assumption or assess it, but the plots below show you what this could look like. The sketch in Figure 2.125 attempts to show the idea of normal distributions that are centered at the true regression line, all with the same shape and variance that is an assumption of the regression model. Figure 2.126 contains simulated realizations from a normal distribution of 20 subjects at each Beer level around the assumed true regression line with two different residual SEs of 0.02 and 0.06. The original BAC model has a residual SE of 0.02 but had many fewer observations at each Beer value.
(ref:fig7-1) Sketch of assumed normal distributions for the responses centered at the regression line.
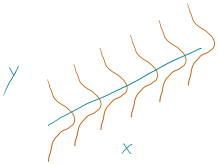
Figure 2.125: (ref:fig7-1)
(ref:fig7-2) Simulated data for Beers and BAC assuming two different residual standard errors (0.02 and 0.06).
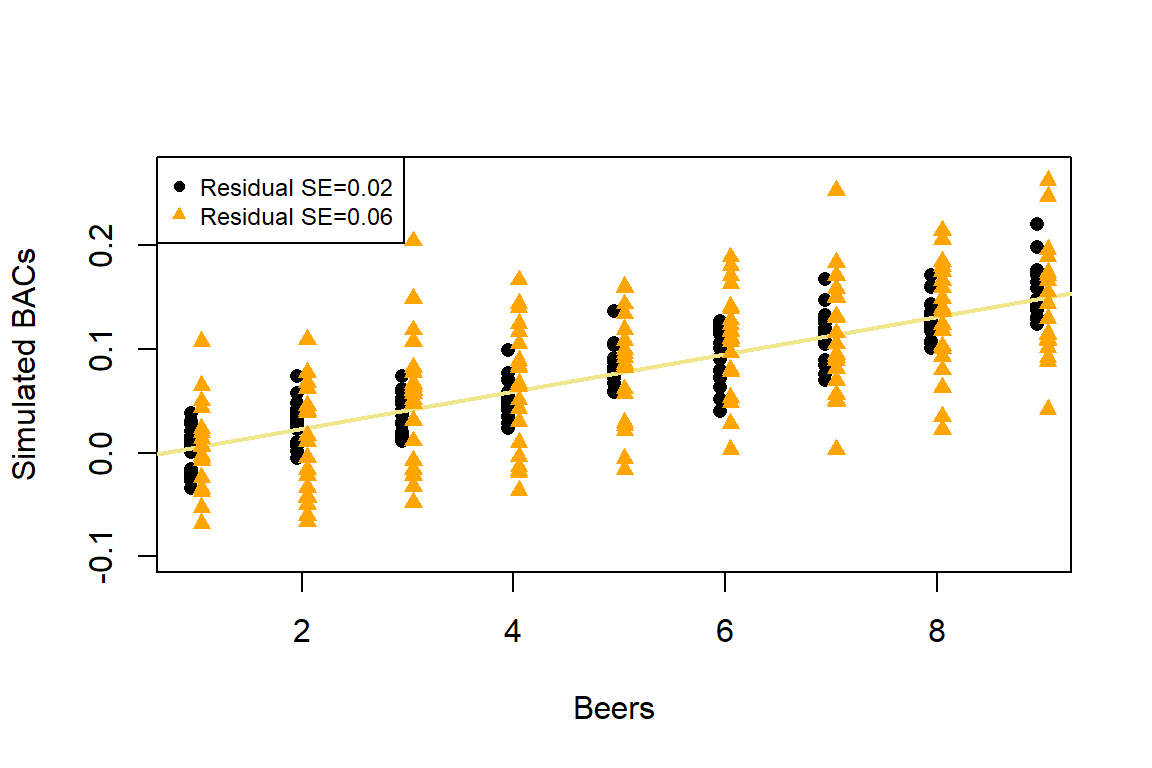
Figure 2.126: (ref:fig7-2)
Along with getting the idea that regression models define normal distributions in the y-direction that are centered at the regression line, you can also get a sense of how variable samples from a normal distribution can appear. Each distribution of 20 subjects at each \(x\) value came from a normal distribution but there are some of those distributions that might appear to generate small outliers and have slightly different variances. This can help us to remember to not be too particular when assessing assumptions and allow for some variability in spreads and a few observations from the tails of the distribution to occasionally arise.
In sampling from the population, we expect some amount of variability of each estimator around its true value. This variability leads to the potential variability in estimated regression lines (think of a suite of potential estimated regression lines that would be created by different random samples from the same population). Figure 2.127 contains the true regression line (bold, red) and realizations of the estimated regression line in simulated data based on results similar to the real data set. This variability due to random sampling is something that needs to be properly accounted for to use the single estimated regression line to make inferences about the true line and parameters based on the sample-based estimates. The next sections develop those inferential tools.
(ref:fig7-3) Variability in realized regression lines based on sampling
variation. Light grey lines are simulated realizations assuming the bold (red) line is the true SLR model and variability is similar to the original BAC data set. Simulated observations from the estimated models using the simulate function as was used in Chapter 2 were used to create this plot.
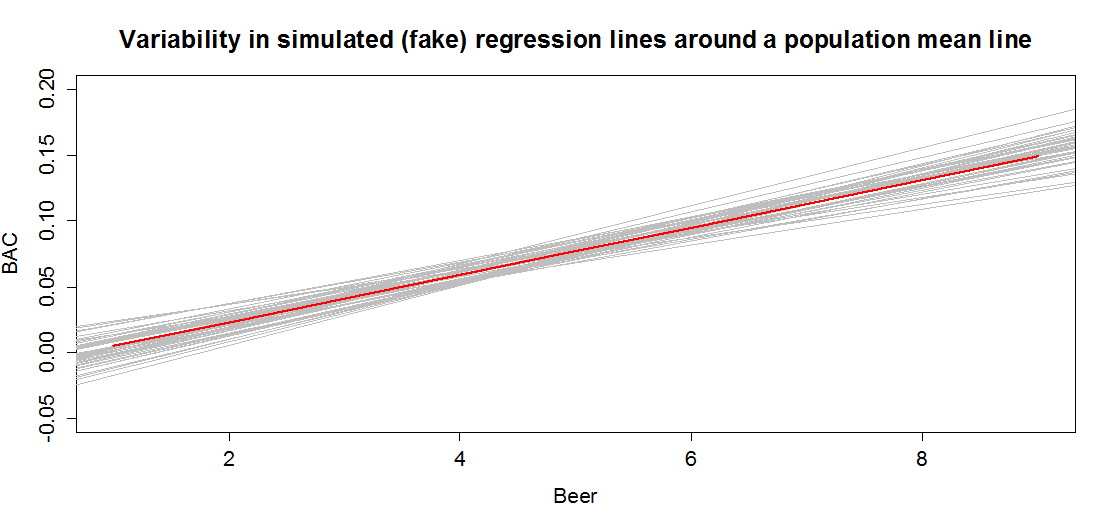
Figure 2.127: (ref:fig7-3)