- Cover
- Acknowledgments
- 1 Preface
- 2 (R)e-Introduction to statistics
- 2.1 Histograms, boxplots, and density curves
- 2.2 Pirate-plots
- 2.3 Models, hypotheses, and permutations for the two sample mean situation
- 2.4 Permutation testing for the two sample mean situation
- 2.5 Hypothesis testing (general)
- 2.6 Connecting randomization (nonparametric) and parametric tests
- 2.7 Second example of permutation tests
- 2.8 Reproducibility Crisis: Moving beyond p < 0.05, publication bias, and multiple testing issues
- 2.9 Confidence intervals and bootstrapping
- 2.10 Bootstrap confidence intervals for difference in GPAs
- 2.11 Chapter summary
- 2.12 Summary of important R code
- 2.13 Practice problems
- 3 One-Way ANOVA
- 3.1 Situation
- 3.2 Linear model for One-Way ANOVA (cell-means and reference-coding)
- 3.3 One-Way ANOVA Sums of Squares, Mean Squares, and F-test
- 3.4 ANOVA model diagnostics including QQ-plots
- 3.5 Guinea pig tooth growth One-Way ANOVA example
- 3.6 Multiple (pair-wise) comparisons using Tukey’s HSD and the compact letter display
- 3.7 Pair-wise comparisons for the Overtake data
- 3.8 Chapter summary
- 3.9 Summary of important R code
- 3.10 Practice problems
- 4 Two-Way ANOVA
- 4.1 Situation
- 4.2 Designing a two-way experiment and visualizing results
- 4.3 Two-Way ANOVA models and hypothesis tests
- 4.4 Guinea pig tooth growth analysis with Two-Way ANOVA
- 4.5 Observational study example: The Psychology of Debt
- 4.6 Pushing Two-Way ANOVA to the limit: Un-replicated designs and Estimability
- 4.7 Chapter summary
- 4.8 Summary of important R code
- 4.9 Practice problems
- 5 Chi-square tests
- 5.1 Situation, contingency tables, and tableplots
- 5.2 Homogeneity test hypotheses
- 5.3 Independence test hypotheses
- 5.4 Models for R by C tables
- 5.5 Permutation tests for the \(X^2\) statistic
- 5.6 Chi-square distribution for the \(X^2\) statistic
- 5.7 Examining residuals for the source of differences
- 5.8 General protocol for \(X^2\) tests
- 5.9 Political party and voting results: Complete analysis
- 5.10 Is cheating and lying related in students?
- 5.11 Analyzing a stratified random sample of California schools
- 5.12 Chapter summary
- 5.13 Summary of important R commands
- 5.14 Practice problems
- 6 Correlation and Simple Linear Regression
- 6.1 Relationships between two quantitative variables
- 6.2 Estimating the correlation coefficient
- 6.3 Relationships between variables by groups
- 6.4 Inference for the correlation coefficient
- 6.5 Are tree diameters related to tree heights?
- 6.6 Describing relationships with a regression model
- 6.7 Least Squares Estimation
- 6.8 Measuring the strength of regressions: R2
- 6.9 Outliers: leverage and influence
- 6.10 Residual diagnostics – setting the stage for inference
- 6.11 Old Faithful discharge and waiting times
- 6.12 Chapter summary
- 6.13 Summary of important R code
- 6.14 Practice problems
- 7 Simple linear regression inference
- 7.1 Model
- 7.2 Confidence interval and hypothesis tests for the slope and intercept
- 7.3 Bozeman temperature trend
- 7.4 Randomization-based inferences for the slope coefficient
- 7.5 Transformations part I: Linearizing relationships
- 7.6 Transformations part II: Impacts on SLR interpretations: log(y), log(x), & both log(y) & log(x)
- 7.7 Confidence interval for the mean and prediction intervals for a new observation
- 7.8 Chapter summary
- 7.9 Summary of important R code
- 7.10 Practice problems
- 8 Multiple linear regression
- 8.1 Going from SLR to MLR
- 8.2 Validity conditions in MLR
- 8.3 Interpretation of MLR terms
- 8.4 Comparing multiple regression models
- 8.5 General recommendations for MLR interpretations and VIFs
- 8.6 MLR inference: Parameter inferences using the t-distribution
- 8.7 Overall F-test in multiple linear regression
- 8.8 Case study: First year college GPA and SATs
- 8.9 Different intercepts for different groups: MLR with indicator variables
- 8.10 Additive MLR with more than two groups: Headache example
- 8.11 Different slopes and different intercepts
- 8.12 F-tests for MLR models with quantitative and categorical variables and interactions
- 8.13 AICs for model selection
- 8.14 Case study: Forced expiratory volume model selection using AICs
- 8.15 Chapter summary
- 8.16 Summary of important R code
- 8.17 Practice problems
- 9 Case studies
- 9.1 Overview of material covered
- 9.2 The impact of simulated chronic nitrogen deposition on the biomass and N2-fixation activity of two boreal feather moss–cyanobacteria associations
- 9.3 Ants learn to rely on more informative attributes during decision-making
- 9.4 Multi-variate models are essential for understanding vertebrate diversification in deep time
- 9.5 What do didgeridoos really do about sleepiness?
- 9.6 General summary
- References
6.1 Relationships between two quantitative variables
The independence test in Chapter ?? provided a technique for assessing evidence of a relationship between two categorical variables. The terms relationship and association are synonyms that, in statistics, imply that particular values on one variable tend to occur more often with some other values of the other variable or that knowing something about the level of one variable provides information about the patterns of values on the other variable. These terms are not specific to the “form” of the relationship – any pattern (strong or weak, negative or positive, easily described or complicated) satisfy the definition. There are two other aspects to using these terms in a statistical context. First, they are not directional – an association between \(x\) and \(y\) is the same as saying there is an association between \(y\) and \(x\). Second, they are not causal unless the levels of one of the variables are randomly assigned in an experimental context. We add to this terminology the idea of correlation between variables \(x\) and \(y\). Correlation, in most statistical contexts, is a measure of the specific type of relationship between the variables: the linear relationship between two quantitative variables90. So as we start to review these ideas from your previous statistics course, remember that associations and relationships are more general than correlations and it is possible to have no correlation where there is a strong relationship between variables. “Correlation” is used colloquially as a synonym for relationship but we will work to reserve it for its more specialized usage here to refer specifically to the linear relationship.
Assessing and then modeling relationships between quantitative variables drives
the rest of the chapters,
so we should get started with some motivating examples to start to think about
what relationships between quantitative variables “look like”… To motivate
these methods, we will start with a study of the effects of beer consumption on
blood alcohol levels (BAC, in grams of alcohol per deciliter of blood). A group
of \(n=16\) student volunteers at The Ohio State University drank a
randomly assigned number of beers91.
Thirty minutes later, a police officer measured their BAC. Your instincts, especially
as well-educated college students with some chemistry knowledge, should inform
you about the direction of this relationship – that there is a positive
relationship between Beers and BAC. In other words, higher values of
one variable are associated with higher values of the other. Similarly,
lower values of one are associated with lower values of the other.
In fact there are online calculators that tell you how much your BAC increases
for each extra beer consumed (for example:
http://www.craftbeer.com/beer-studies/blood-alcohol-content-calculator
if you plug in 1 beer). The increase
in \(y\) (BAC) for a 1 unit increase in \(x\) (here, 1 more beer) is an example of a
slope coefficient that is applicable if the relationship between the
variables is linear and something that will be
fundamental in what is called a simple linear regression model.
In a
simple linear regression model (simple means that there is only one explanatory
variable) the slope is the expected change in the mean response for a one unit
increase in the explanatory variable. You could also use the BAC calculator and
the models that we are going to develop to pick a total number of beers you
will consume and get a predicted BAC, which employs the entire equation we will estimate.
Before we get to the specifics of this model and how we measure correlation, we
should graphically explore the relationship between Beers and BAC in a scatterplot.
Figure 2.100 shows a scatterplot of the results that display
the expected positive relationship. Scatterplots display the response pairs for
the two quantitative variables with the
explanatory variable on the x-axis and the response variable on the y-axis. The
relationship between Beers and BAC appears to be relatively linear but
there is possibly more variability than one might expect. For example, for
students consuming 5 beers, their BACs range from 0.05 to 0.10. If you look
at the online BAC calculators, you will see that other factors such as weight,
sex, and beer percent alcohol can impact
the results. We might also be interested in previous alcohol consumption. In
Chapter ??, we will learn how to estimate the relationship between
Beers and BAC after correcting or controlling for those “other variables” using
multiple linear regression, where we incorporate more than one
quantitative explanatory variable into the linear model (somewhat like in the
2-Way ANOVA).
Some of this variability might be hard or impossible to explain
regardless of the other variables available and is considered unexplained variation
and goes into the residual errors in our models, just like in the ANOVA models.
To make scatterplots as in Figure 2.100, you can simply92 use
plot(y~x, data=...).
require(readr)
BB <- read_csv("http://www.math.montana.edu/courses/s217/documents/beersbac.csv")
plot(BAC~Beers, data=BB, pch=16, col=30)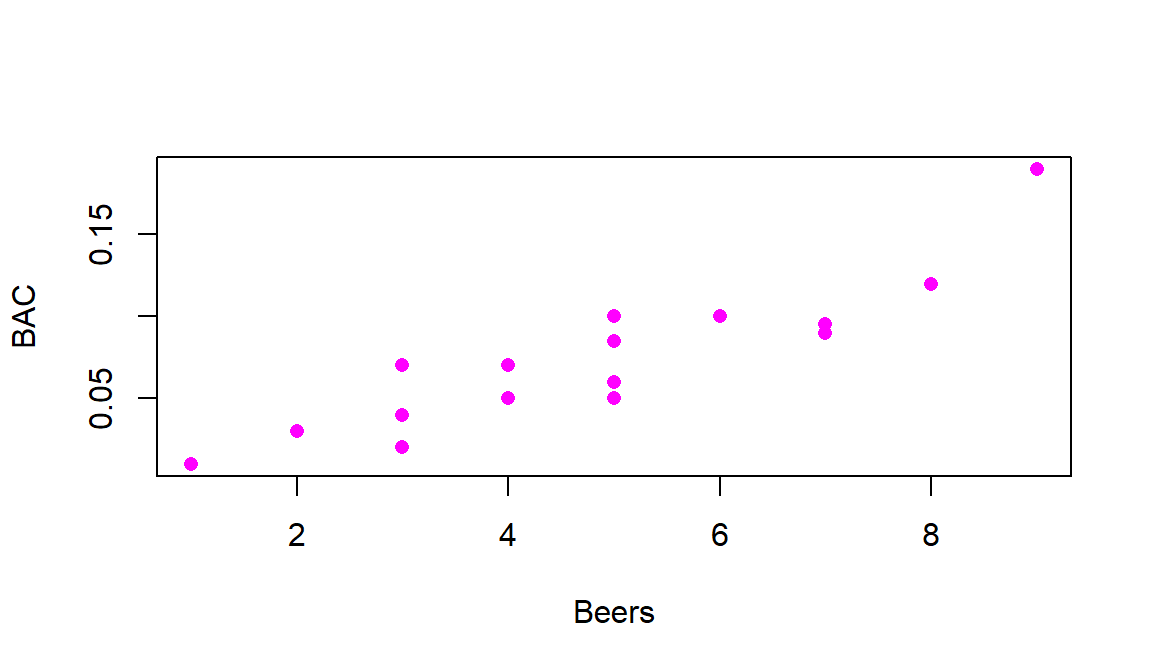
Figure 2.100: Scatterplot of Beers consumed versus BAC.
There are a few general things to look for in scatterplots:
Assess the \(\underline{\textbf{direction of the relationship}}\) – is it positive or negative?
Consider the \(\underline{\textbf{strength of the relationship}}\). The general idea of assessing strength visually is about how hard or easy it is to see the pattern. If it is hard to see a pattern, then it is weak. If it is easy to see, then it is strong.
Consider the \(\underline{\textbf{linearity of the relationship}}\). Does it appear to curve or does it follow a relatively straight line? Curving relationships are called curvilinear or nonlinear and can be strong or weak just like linear relationships – it is all about how tightly the points follow the pattern you identify.
Check for \(\underline{\textbf{unusual observations -- outliers}}\) – by looking for points that don’t follow the overall pattern. Being large in \(x\) or \(y\) doesn’t mean that the point is an outlier. Being unusual relative to the overall pattern makes a point an outlier in this setting.
Check for \(\underline{\textbf{changing variability}}\) in one variable based on values of the other variable. This will tie into a constant variance assumption later in the regression models.
Finally, look for \(\underline{\textbf{distinct groups}}\) in the scatterplot. This might suggest that observations from two populations, say males and females, were combined but the relationship between the two quantitative variables might be different for the two groups.
Going back to Figure 2.100 it appears that there is a
moderately strong linear
relationship between Beers and BAC – not weak but with some variability
around what appears to be a fairly clear to see straight-line relationship. There might even be a
hint of a nonlinear relationship in the higher beer values. There are no clear
outliers because the observation at 9 beers seems to be following the overall
pattern fairly closely. There is little evidence of non-constant variance
mainly because of the limited size of the data set – we’ll check this with
better plots later. And there are no clearly distinct groups in this plot, possibly
because the # of beers was randomly assigned. These data have one more
interesting feature to be noted – that subjects managed to consume 8 or 9
beers. This seems to be a large number. I have never been able to trace this
data set to the original study so it is hard to know if (1) they had this study
approved by a human subjects research review board to make sure it was “safe”,
(2) every subject in the study was able to consume their randomly assigned
amount, and (3) whether subjects were asked to show up to the study with BACs
of 0. We also don’t know the exact alcohol concentration of the beer consumed or
volume. So while this is a fun example to start these methods with, a better version of this data set would be nice…
In making scatterplots, there is always a choice of a variable for the x-axis and the y-axis. It is our convention to put explanatory or independent variables (the ones used to explain or predict the responses) on the x-axis. In studies where the subjects are randomly assigned to levels of a variable, this is very clearly an explanatory variable, and we can go as far as making causal inferences with it. In observational studies, it can be less clear which variable explains which. In these cases, make the most reasonable choice based on the observed variables but remember that, when the direction of relationship is unclear, you could have switched the axes and thus the implication of which variable is explanatory.
There are measures of correlation between categorical variables but when statisticians say correlation they mean correlation of quantitative variables. If they are discussing correlations of other types, they will make that clear.↩
Some of the details of this study have been lost, so we will assume that the subjects were randomly assigned and that a beer means a regular sized can of beer and that the beer was of regular strength. We don’t know if any of that is actually true. It would be nice to repeat this study to know more details and possibly have a larger sample size but I doubt if our institutional review board would allow students to drink as much as 9 beers.↩
I added
pch=16, col=30to fill in the default circles and make the points in something other than black, an entirely unnecessary addition here.↩